Kylin源码解析系列目录
Hexo和Next升级
Guide to Using Apache Kudu and Performance Comparison with HDFS
[toc]
Apache Kudu是一个开源的列式存储引擎。它保证了低延迟的随机访问和分析查询的有效执行。kudu存储引擎支持通过Cloudera Impala,Spark以及Java,C ++和Python API进行访问。
本文的目的是记录我在探索Apache Kudu方面的经验,了解它的局限性,并进行一些实验以比较Apache Kudu存储与HDFS存储的性能。
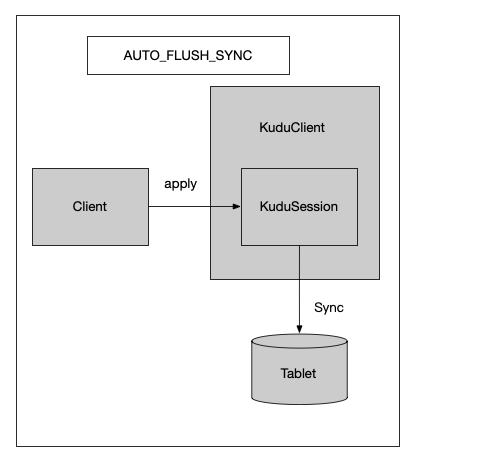
Kudu三种FlushMode对比分析
Kylin源码解析-提取事实表唯一列

方法介绍
这一步是Kylin运行MR任务来提取使用字典编码(rowkey配置也的编码类型为dict)的维度列的唯一值。
1 | //构建方法 |
Kylin源码解析-生成Hive宽表及其他操作
前一章介绍了构建引擎相关的原理,本章介绍其中的Hive输入的相关操作。
Hive相关主要分为以下几步:
- 生成Hive宽表
- 均匀打散上面生成的宽表
- 物化lookup维表
Kylin源码解析-构建引擎实现原理
从本章节开始,开始深入探讨BatchCubingJobBuilder2的build方法。
在开始之前,先上一个类图。在途中,核心就是BatchCubingJobBuilder2类,这个类的实例的创建,在前面的文章(Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想)中有详细介绍,这里不再赘述。
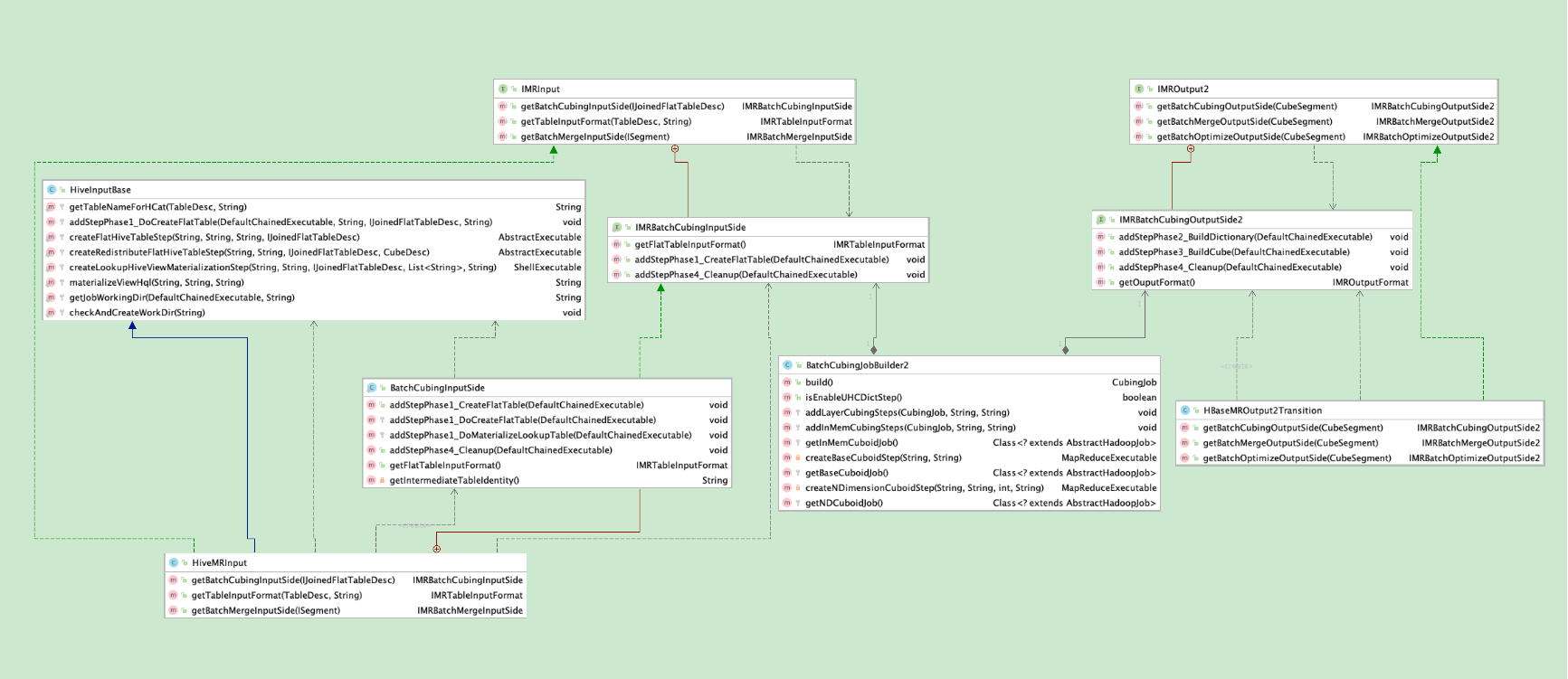
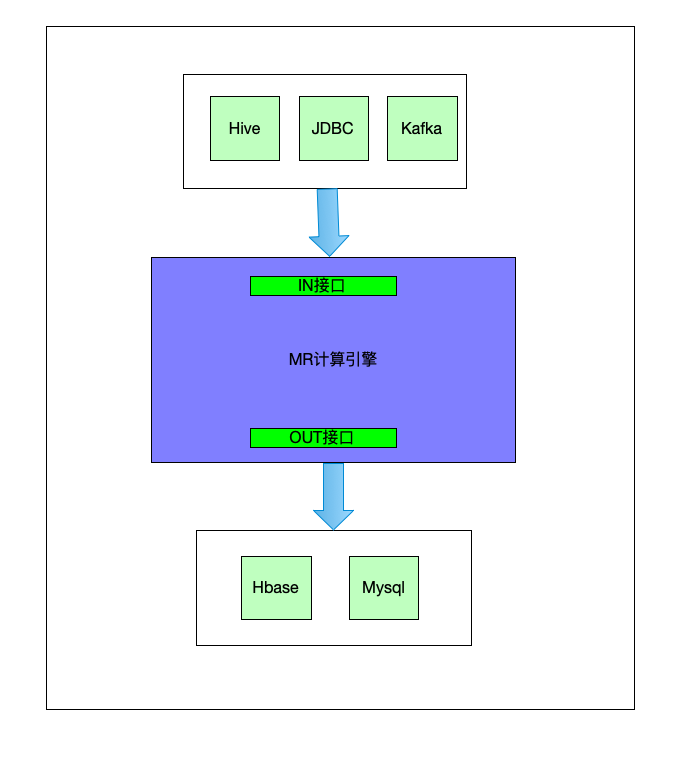
如下图,这个BatchCubingJobBuilder2就是这个引擎,它串起了数据源(输入)和存储(输出),而它本身,就类似一个加工程序,按照指定的操作流程对数据源进行加工,然后将加工好的数据存入到存储介质当中。
这里可以打个不太恰当的比喻,把这个引擎比喻成一个面条机,输入则是面粉,面粉的则有分为很多种类,然后经过引擎加工,输出到不同的容器当中,比如盆子或者包装袋中。
它的输入和输出是一个可插拔的,输入的面粉种类可以随意换,输出的容器也可以随意换,但是里面加工步骤是不变的,都是先加水,后搅拌,然后在挤压…最后生成面条。
Kylin源码解析-kylin构建任务生成与调度执行
本文介绍kylin的构建任务的生成流程,包括前端如何请求的kylin服务端,服务端内部怎么调用生成任务并返回给前端以及内部如何调度的。
Kylin源码解析-kylin构建流程总览
在上文Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想 中详细介绍了Kylin构建任务的生成和调度,其中讲到,会调用BatchCubingJobBuilder2的build方法,生成一个CubingJob实例,本文就介绍下这个build方法大致流程,并描述整个构建过程。 如下图所示,分为四个阶段和十四步。
Kylin源码解析-构建层级分析
本文主要分析,在Kylin层级构建的时候,这个层级的获取流程