
在上文Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想 中详细介绍了Kylin构建任务的生成和调度,其中讲到,会调用BatchCubingJobBuilder2的build方法,生成一个CubingJob实例,本文就介绍下这个build方法大致流程,并描述整个构建过程。 如下图所示,分为四个阶段和十四步。
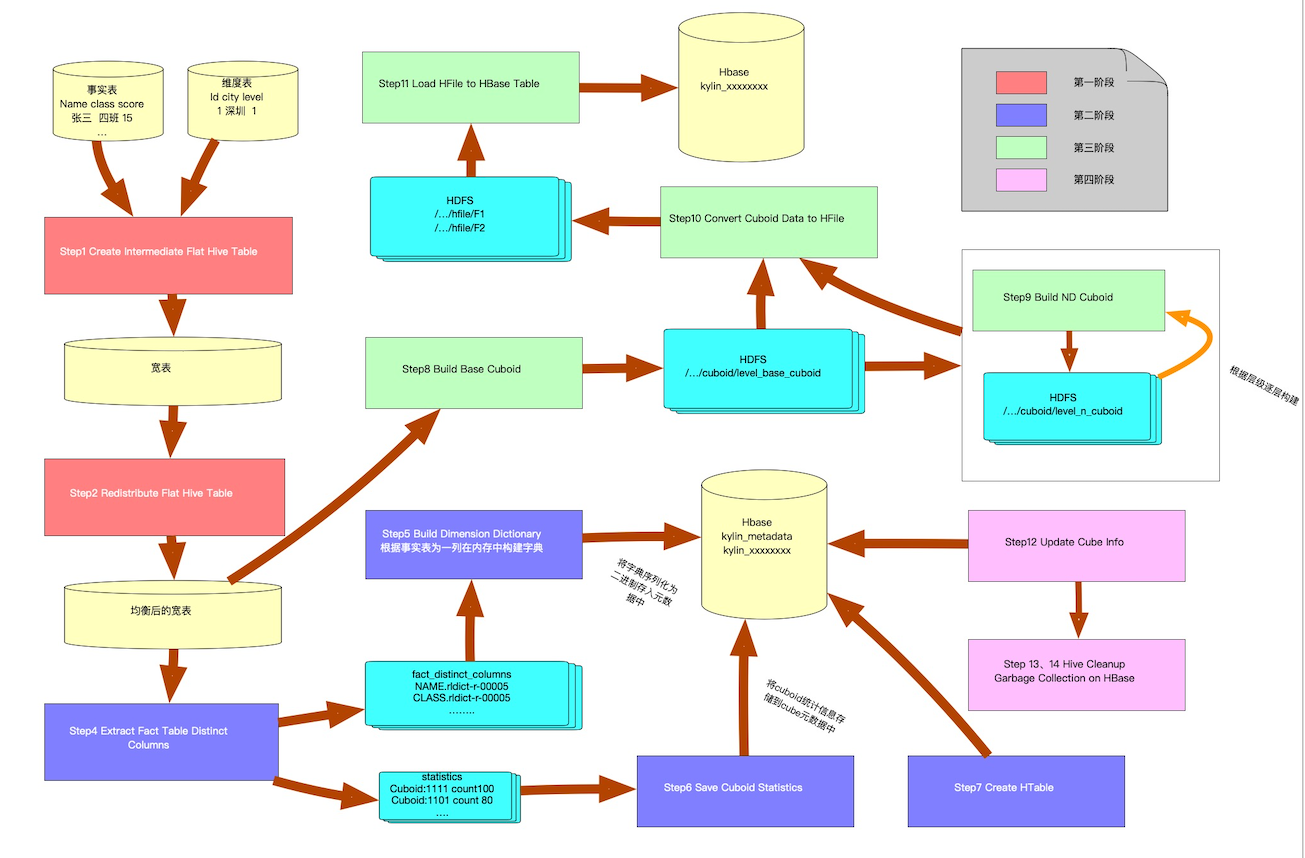
阶段一:Create Flat Table & Materialize Hive View in Lookup Tables
第一步:Create Intermediate Flat Hive Table
这一步将数据从Hive表中提取出来(会join所有的维表),并且一起插入到一张临时中间宽表中。会加上时间分区条件确保只有指定时间的数据才会被提取。
第二步:Redistribute Flat Hive Table
上一步,hive在hdfs上的目录里生成了数据文件,但是不均匀,有的很大,有的很小,有的是空的,非常可能在后面的MR程序中导致数据倾斜,有的Mapper很快跑完,其他就很慢,kylin增加了这一步“重新分发”数据。
第三步:Materialize Hive View in Lookup Tables
阶段二:Build Dictionary
第四步:Extract Fact Table Distinct Columns
提取事实表的为一列,这一步kylin运行MR任务提取使用字典编码的维度列的谓一致。这一步还顺带通过HHL计数器手机cube的统计数据,用于估算每个cuboid的行数。
第五步:Build Dimension Dictionary
这一步会根据前面的提取的维度列的谓一致,在内存里面构建字典,然后将字典存在hbase当中,并且修改cube的元数据。
第六步:Save Cuboid Statistics
保存第四步生成的统计数据到cube元数据中。
第七步:Create HTable
阶段三:Build Cube
在hbase中创建htable。
第八步:Build Base Cuboid
这一步用Hive的中间表的数据构建基础cuboid,是“layer”构建cube算法中的第一步。后面的构建会依赖于这个base cuboid。
第九步:Build ND Cuboid
构建N维cuboid,这一步是一个逐层构建的过程,是根据cuboid数组计算出的一个层次,并循环这个层次数层层构建。每一步都会以前一步的输出作为输入,然后去掉一个维度以聚合得到一个子的cuboid。所以层级越往后,构建速度会越快。
第十步:Convert Cuboid Data to HFile
这一步使用MR任务将cuboid文件(序列文件格式)转换为hbase的hfile格式。
第十一步: Load HFile to HBase Table
将上一步生成的hfile使用hbase api导入到region server,轻量快速。
阶段四:Update Metadata & Cleanup
第十二步:Update Cube Info
修改kylin元数据,将对应的cube segment标记为ready。
第十三步:Hive Cleanup
将中间宽表从Hive删除。
第十四步:Garbage Collection on HBase
Hbase上的垃圾数据删除。
本文先大致列出相关的阶段和步骤,在后面文章中每个步骤都会详细介绍。
参考文档
Kylin源码解析系列目录
构建引擎系列
1、Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想
2、Kylin源码解析-kylin构建流程总览 | 编程狂想
4、Kylin源码解析-生成Hive宽表及其他操作 | 编程狂想
7、Kylin源码解析-构建数据字典和生成Cuboid统计数据
8、Kylin源码解析-生成Hbase表
9、Kylin源码解析-构建Cuboid
10、Kylin源码解析-转换HDFS为Hfile
11、Kylin源码解析-加载Hfile到Hbase中
12、Kylin源码解析-修改元数据以及其他清理工作