[toc]
Apache Kudu是一个开源的列式存储引擎。它保证了低延迟的随机访问和分析查询的有效执行。kudu存储引擎支持通过Cloudera Impala,Spark以及Java,C ++和Python API进行访问。
本文的目的是记录我在探索Apache Kudu方面的经验,了解它的局限性,并进行一些实验以比较Apache Kudu存储与HDFS存储的性能。
使用Cloudera Manager安装Apache Kudu
以下是Cloudera Manager Apache Kudu文档的链接,可用于在Cloudera Manager管理的集群上安装Apache Service。
Apache Kudu指南| 5.14.x | Cloudera文档Cloudera Manager,Cloudera Navigator和CDH 5的配置要求www.cloudera.com
访问Apache必须通过Impala
可以使用Impala在kudu存储表中创建,更新,删除和插入。可以在这里找到良好的文档https://www.cloudera.com/documentation/kudu/5-10-x/topics/kudu_impala.html。
创建一个新表:
1 | CREATE TABLE new_kudu_table(id BIGINT, name STRING, PRIMARY KEY(id))PARTITION BY HASH PARTITIONS 16STORED AS KUDU; |
对数据执行插入,更新和删除:
1 | --insert into that table |
也可以使用CREATE TABLE DDL从现有的Hive表中创建kudu表。在下面的示例脚本中,如果已经存在表 movies,则可以按以下方式创建Kudu支持的表:
1 | CREATE TABLE movies_kudu |
创建Kudu表时的限制:
不支持的数据类型:如果表具有VARCHAR(),DECIMAL(),DATE和复杂数据类型(MAP,ARRAY,STRUCT,UNION),则从现有的配置单元表创建表时,则在kudu中不支持这些数据类型。任何选择这些列并创建kudu表的尝试都将导致错误。如果使用**SELECT ***创建Kudu表,那么不兼容的非主键列将被删除到最终表中。
主键:必须先在表模式中指定主键。从另一个主键列不在第一位的现有表中创建Kudu表时,请在create table语句中的select语句中对列进行重新排序。另外,主键列不能为空。
Access Kudu via Spark
在您的spark项目中添加kudu_spark允许您创建一个kuduContext,可用于创建Kudu表并将数据加载到其中。请注意,这只会在Kudu中创建表,并且如果您要通过Impala查询此表,则必须创建一个外部表,并按名称引用此Kudu表。
以下是使用Kudu spark通过spark在Kudu中创建表的简单演练。让我们从添加依赖关系开始,
1 | <properties> |
接下来,创建一个KuduContext,如下所示。由于SparkKudu的库是用Scala编写的,因此我们必须应用适当的转换,例如将JavaSparkContext转换为与Scala兼容的
1 | import org.apache.kudu.spark.kudu.KuduContext; |
如果我们有一个要存储到Kudu的数据框,则可以执行以下操作:
1 | import org.apache.kudu.client.CreateTableOptions; |
通过Spark使用Kudu时的局限性:
不支持的数据类型: Kudu不支持某些复杂的数据类型,并且通过Spark加载时会通过异常使用它们创建表。 Spark确实设法将VARCHAR()转换为弹簧类型,但是其他类型(ARRAY,DATE,MAP,UNION和DECIMAL)将不起作用。
如果要通过Impala访问,则需要创建外部表:使用上述示例在Kudu中创建的表仅驻留在Kudu存储中,并且不反映为Impala表。要通过Impala查询该表,我们必须创建一个指向Kudu表的外部表。
1 | CREATE EXTERNAL TABLE IF NOT EXISTS <impala_table_name> |
Apache Kudu和HDFS性能比较
实验目的
该实验的目的是在加载数据和运行复杂的分析查询方面比较Apache Kudu和HDFS。
实验设置
- 使用的数据集:TPC Benchmark™H(TPC-H)是决策支持基准,它模拟典型的业务数据集和一组复杂的分析查询。可以在https://github.com/hortonworks/hive-testbench上找到生成此数据集并将其加载到配置单元的好资源。该数据集有8个表,并且可以从2 Gb开始以不同的比例生成。为了该测试的目的,生成了20Gb的总数据。
- 群集设置:群集具有4个Amazon EC2实例,其中1个主实例(m4.xlarge)和3个数据节点(m4.large)。每个群集具有1个大小为150 Gb的磁盘。集群通过Cloudera Manager进行管理。
数据加载性能:
表1.显示了使用Apache Spark加载到Kudu与Hdfs之间的时间(以秒为单位)。Kudu表使用主键进行哈希分区。

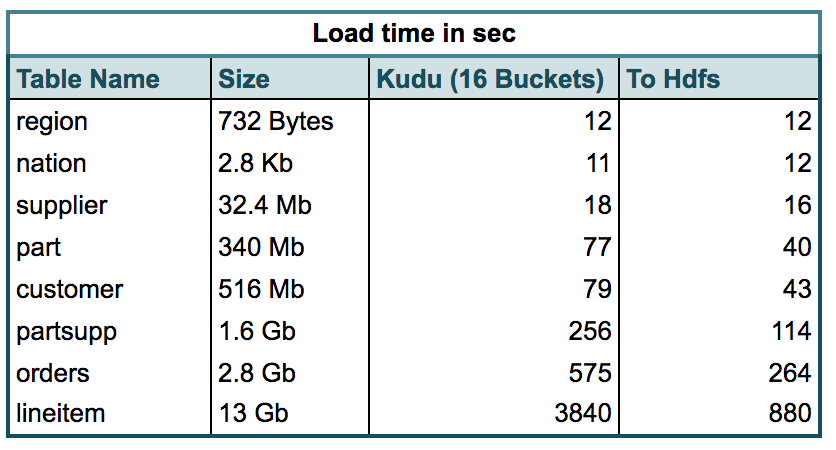
表1.基准数据集中表的加载时间
观察结果:从上表中可以看到,小型Kudu表的加载速度几乎与Hdfs表一样快。但是,随着大小的增加,我们确实看到加载时间变成了Hdfs的两倍,最大的表格行项目占用的加载时间是加载时间的4倍。
分析查询效果:
TPC-H Suite包含一些基准分析查询。使用Impala针对HDFS Parquet存储表,Hdfs逗号分隔存储和Kudu(主键上的16和32 Bucket Hash分区)运行查询。记录了每个查询的运行时,下面的图表以秒为单位显示了这些运行时间的比较。
比较Kudu和HDFS Parquet:

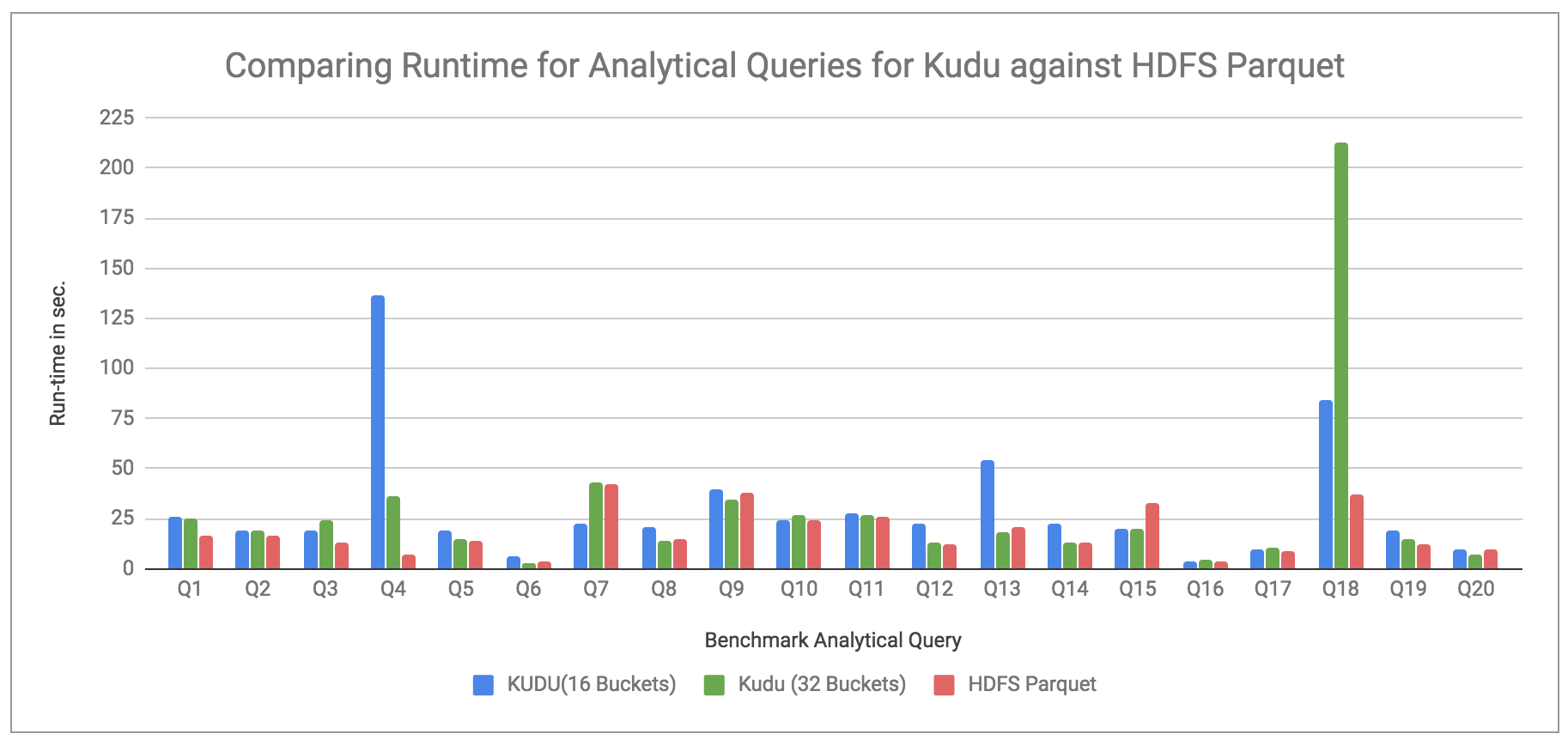
图1.在Kudu和HDFS Parquet上运行分析查询
观察结果:图1比较了在Kudu和HDFS Parquet存储的表上运行基准查询的运行时。我们可以看到,Kudu存储表的性能几乎与HDFS Parquet存储表一样好,除了某些查询(Q4,Q13,Q18)外,与后者相比,它们花费的时间要长得多。
比较Kudu与HDFS逗号分隔的存储文件:

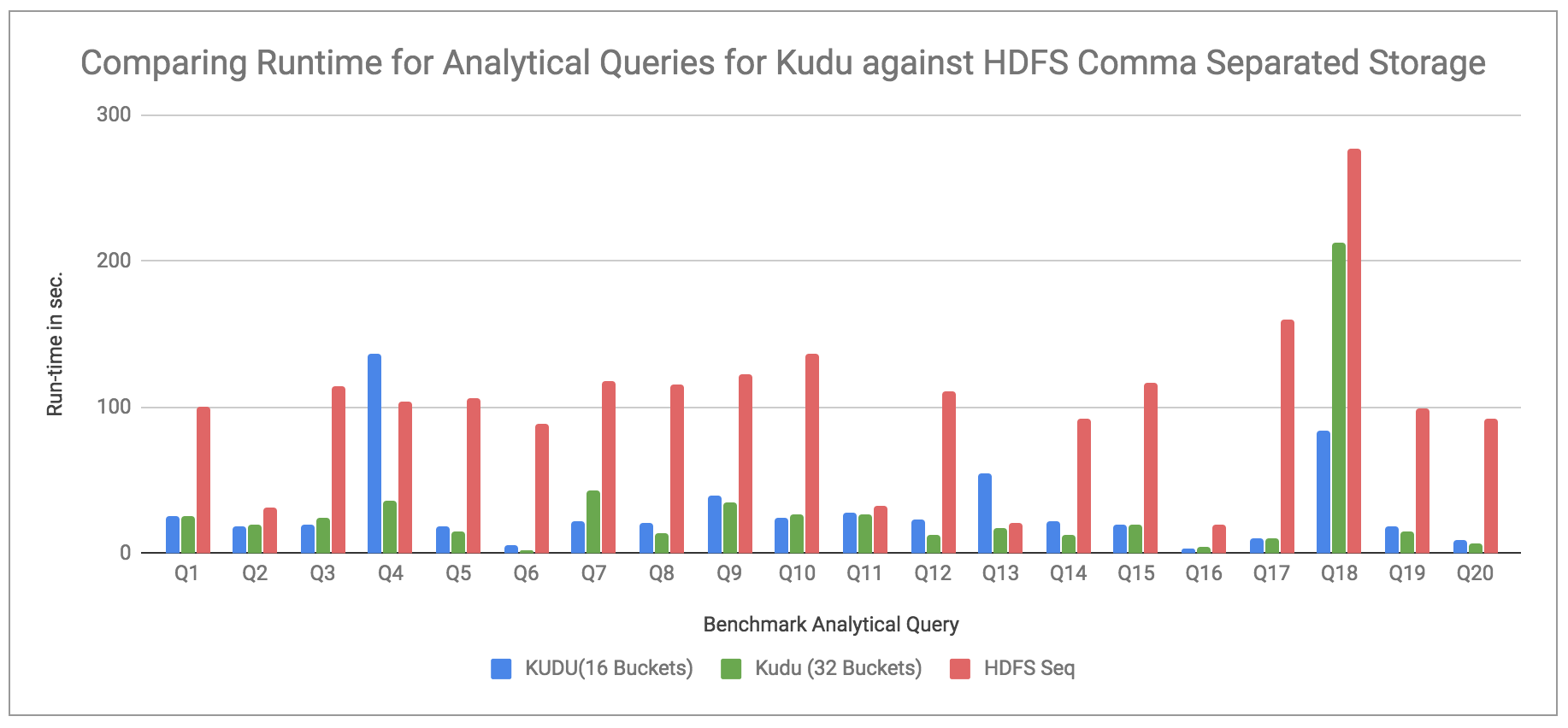
图2.在Kudu和HDFS逗号分隔文件上运行分析查询
观察结果:图2将kudu运行时(与图1相同)与HDFS逗号分隔存储进行了比较。在这里我们可以看到,与Kudu相比,查询在HDFS逗号分隔存储上运行所需的时间要长得多,Kudu(16个存储桶存储)的运行时间平均快5倍,而Kudu(32个存储桶存储)的运行速度要好7倍。平均。
随机访问性能:
Kudu自夸访问随机行时的延迟要低得多。为了对此进行测试,我使用了相同TPC-H基准测试的客户表,并在一个循环中按ID进行了1000次随机访问。这些时间是针对Kudu 4、16和32桶分区数据以及HDFS Parquet存储的数据进行测量的。下图显示了以秒为单位的运行时间。1000随机访问证明了Kudu在随机访问选择方面确实是赢家。

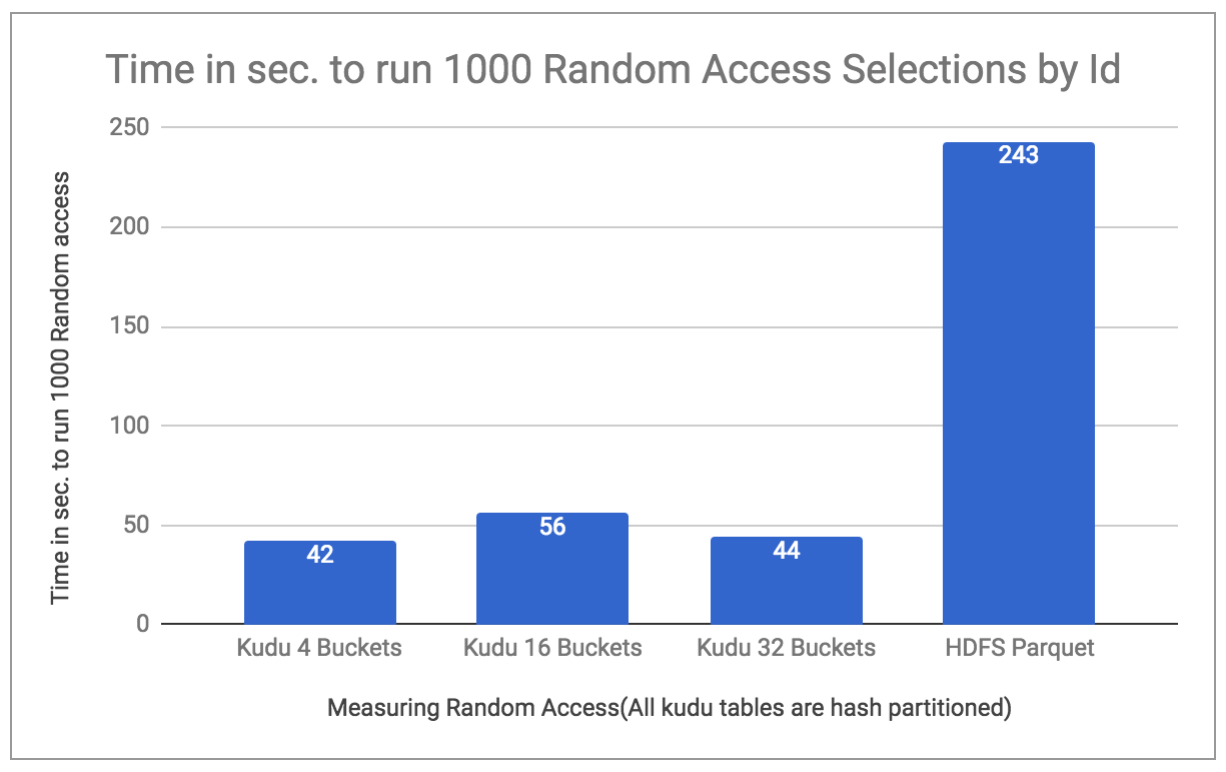
图3.比较随机选择的时间
Kudu更新,插入和删除性能
由于Kudu支持这些附加操作,因此本节将比较这些运行时。该测试的设置类似于上面的随机访问,其中循环运行了1000个操作,并测量了运行时间,可以在下面的表2中看到:


表2.测量各种操作的运行时
结论
只是根据我的探索和实验,写下我对Apache Kudu的想法。
就可访问性而言,我认为有很多选择。可以通过Impala访问该文件,该文件允许创建kudu表并对其进行查询。SparkKudu可在Scala或Java中用于将数据加载到Kudu或从Kudu读取数据作为Data Frame。此外,还提供Java,Python和C ++形式的Kudu客户端API(本博客未涵盖)。
Kudu支持的数据类型有一些限制,如果用例需要为列(例如Array,Map等)使用复杂类型,那么Kudu并不是一个好的选择。
本博客中的实验是用来衡量Kudu在性能方面如何与HDFS相抗衡的测试。
从测试中,我可以看到,尽管与HDFS相比,将数据初始加载到Kudu所需的时间更长,但是在运行分析查询时,它的性能几乎相等,并且对于随机访问数据的性能更好。
总的来说,我可以得出结论,如果对存储的要求与对HDFS的分析查询一样好,并且具有更快的随机访问和RDBMS功能(如更新/删除/插入)的额外灵活性,那么Kudu可以被视为潜在的候选清单。