
前一章介绍了构建引擎相关的原理,本章介绍其中的Hive输入的相关操作。
Hive相关主要分为以下几步:
- 生成Hive宽表
- 均匀打散上面生成的宽表
- 物化lookup维表
生成Hive宽表
这一步将数据从源Hive表提取出来(和所有join的表一起)插入到一个中间平表 。
在构建BatchCubingJobBuilder2的时候,会传入一个IJoinedFlatTableDesc实例,具体类图如下。这个实例代表着一个joined过后的一个宽表描述。他的tableName生成方式是 “kylin_intermediate_” + cubename + cube segementid。

这一步会根据上面的 flatDesc,生成 drop语句(主要为了防止任务一次执行失败后再次执行报错),create语句,以及插入数据的语句。具体生成的cmd命令如下。
1 | hive -e "USE default; |
具体的执行逻辑在 CreateFlatHiveTableStep 这个Executable中,是一个CubingJob的子任务。这一步分为以下几个步骤:
使用 HiveCmdBuilder这个类,依次传入前面的 init、drop、create、insert hql,生成一个hive命令,默认是使用 “hive -e”,如果配置了beeline,则先将上面的hql保存到临时文件中,在生成beeline语句,使用 -f 参数指向刚才生成的临时文件。
使用CliCommandExecutor类执行上面生成的cmd命令,如果kylin配置了kylin.job.use-remote-cli为true,则会获取kylin.job.remote-cli-hostname、kylin.job.remote-cli-port、kylin.job.remote-cli-username、kylin.job.remote-cli-password来进行远程登录执行脚本。
根据第二步,调用Hadoop API获取生成的HDFS文件的大小。
修改kylin_metadata中相关job的大小数据,如下图。

均匀打散上面生成的宽表
在上一步中,只是简单的将数据查出粗来,并且插入到一个平表当中,数据非常不均匀,有的文件大,有的文件小,有的事空的。在上一步,是 insert overwrite语句,所以只会生成 Mapper,没有Reducer。而后面的字典构建和Cuboid构建,是需要依赖这些生成的文件的,会根据这写文件生成相应的Mapper,如果这些文件不均匀,则有可能会导致数据倾斜,有的Mapper很快完成,有的则需要很久。
针对这个问题,Kylin增加一个一个重新打散的操作。这一步的Step类是RedistributeFlatHiveTableStep,是在HiveMRInput中实例化,会传入上一步生成的宽表,以及redistribute的hql语句,这个hql语句是根据cube的配置生成的,默认是按照 cube rowkey列的最前面3个列生成distribute by 语句。如果在配置rowkey的时候指定了 shard by ,则会按照这个字段进行 distribute by。
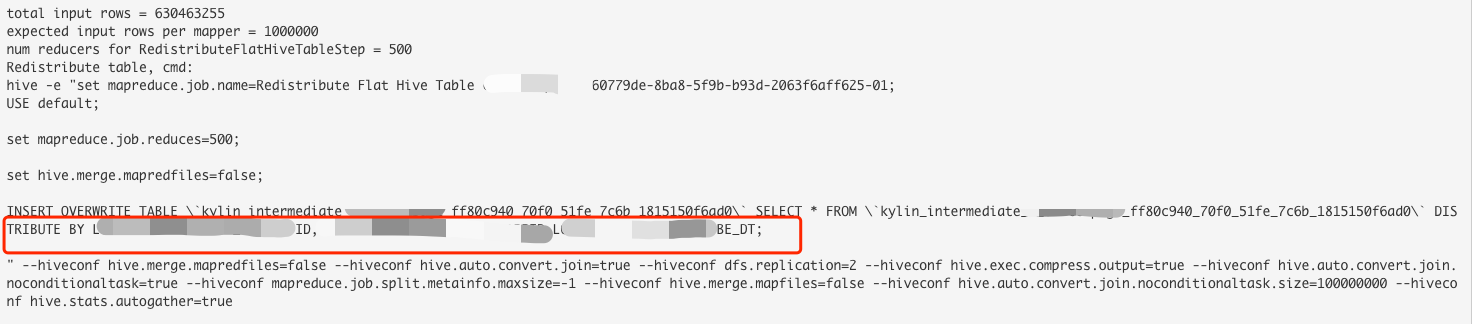
重新分发有下面几个步骤
构建重新分发的语句
- 获取上一步的宽表名称和数据库名称
根据第一步的表名,调用Hive API获取表的行数rowCount
获取kylin配置kylin.engine.mr.mapper-input-rows,默认值为 100000
计算numReducer
1
numReducer = Math.round(rowCount / ((float) mapperInputRows))
根据第一步生成的语句,调用 CliCommandExecutor,执行命令
将执行的命令存入到 Job的元数据信息中,比如下面框线里的就是 stepLogger记录的内容,这个内容或被加入到job元数据中,方便后面定位

获取这个重新分发的表的大小,并写入到Job元数据中。
物化lookup维表
这一步如果lookup表不是视图,就不会执行。
如果维度表是视图,就需要将这个视图物化为一张hivie表,表的存储目录在当前的job的工作空间+jobId目录下面。这个在日常工作中很少碰到,就不详细介绍了。
总结
本章介绍了Hive相关的三个步骤生成Hive宽表、均匀打散宽表和物化lookup维表。 下一章将介绍根据事实表抽取唯一列。
参考
Hive中order、sort、distribute、cluster by区别与联系 - 知乎
Kylin源码解析系列目录
构建引擎系列
1、Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想
2、Kylin源码解析-kylin构建流程总览 | 编程狂想
4、Kylin源码解析-生成Hive宽表及其他操作 | 编程狂想
7、Kylin源码解析-构建数据字典和生成Cuboid统计数据
8、Kylin源码解析-生成Hbase表
9、Kylin源码解析-构建Cuboid
10、Kylin源码解析-转换HDFS为Hfile
11、Kylin源码解析-加载Hfile到Hbase中
12、Kylin源码解析-修改元数据以及其他清理工作