
从本章节开始,开始深入探讨BatchCubingJobBuilder2的build方法。
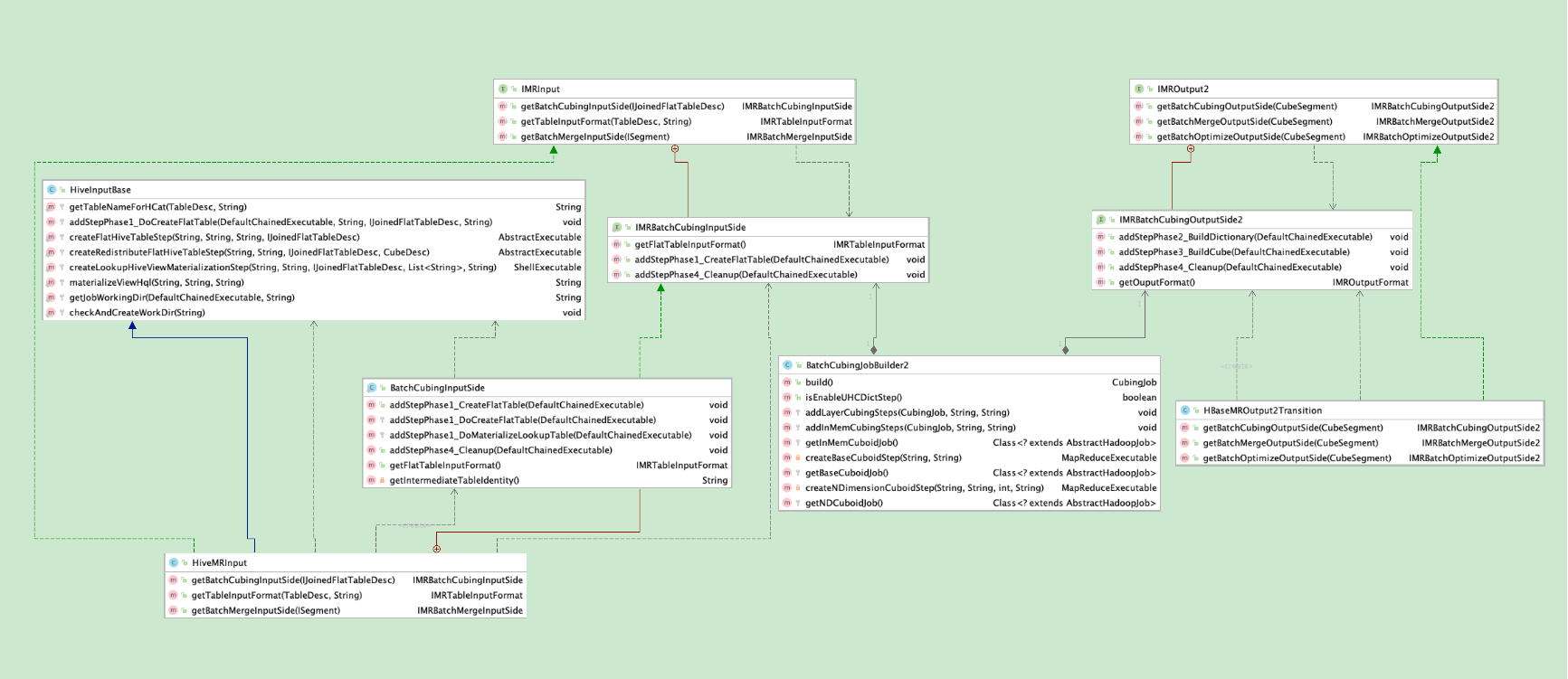
在开始之前,先上一个类图。在途中,核心就是BatchCubingJobBuilder2类,这个类的实例的创建,在前面的文章(Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想)中有详细介绍,这里不再赘述。
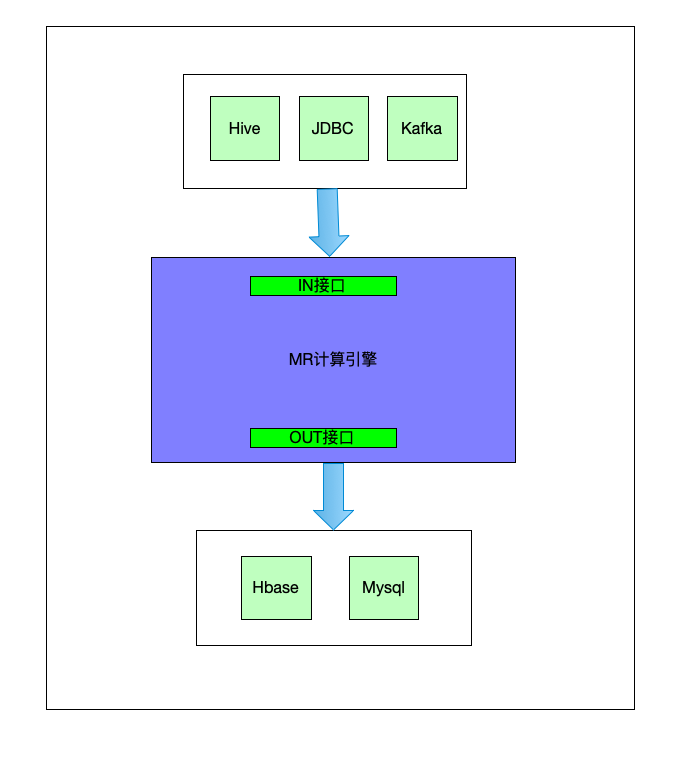
如下图,这个BatchCubingJobBuilder2就是这个引擎,它串起了数据源(输入)和存储(输出),而它本身,就类似一个加工程序,按照指定的操作流程对数据源进行加工,然后将加工好的数据存入到存储介质当中。
这里可以打个不太恰当的比喻,把这个引擎比喻成一个面条机,输入则是面粉,面粉的则有分为很多种类,然后经过引擎加工,输出到不同的容器当中,比如盆子或者包装袋中。
它的输入和输出是一个可插拔的,输入的面粉种类可以随意换,输出的容器也可以随意换,但是里面加工步骤是不变的,都是先加水,后搅拌,然后在挤压…最后生成面条。
现再在看这个类图,IMRBatchCubingInputSide类就是一个输入接口,面粉会源源不断的从这个接口输出,IMRBatchCubingOutputSide2就是一个输出接口,面条会输出到这里来。 IMRBatchCubingInputSide的hive实现是HiveMRinput的内部类BatchCubingInputSide,实现了具体的逻辑,比如执行第一阶段的一些任务。这个HiveMRInput继承了HiveInputBase,实现了IMRInput,而在IMRInput中,则定义了接口,描述了输入端应该在这个构建引擎中所起到的作用,而hive的具体实现都在HiveMRInput类当中。
输出端于此类似,不再赘述。
Kylin源码解析系列目录
构建引擎系列
1、Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想
2、Kylin源码解析-kylin构建流程总览 | 编程狂想
4、Kylin源码解析-生成Hive宽表及其他操作 | 编程狂想
7、Kylin源码解析-构建数据字典和生成Cuboid统计数据
8、Kylin源码解析-生成Hbase表
9、Kylin源码解析-构建Cuboid
10、Kylin源码解析-转换HDFS为Hfile
11、Kylin源码解析-加载Hfile到Hbase中
12、Kylin源码解析-修改元数据以及其他清理工作