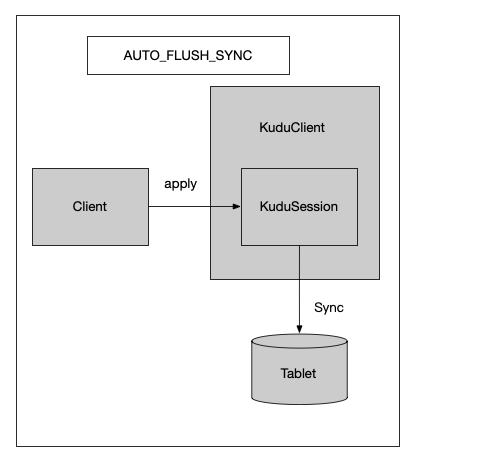
一、FlushMode分类 1.1 AUTO_FLUSH_SYNC 每个 KuduSession方法的apply调用只会在被自动刷新到服务器后返回。不会出现批处理。在这种模式下,flush方法调用不会产生任何影响,因为每个kudusession apply() 返回之前已经刷新了缓冲区,数据已经发往tablet。
这种刷新模式,也就是阻塞式写入,每个调用都要等到tablet返回后才会完成。特点是及时性较好,但是吞吐量不高 。
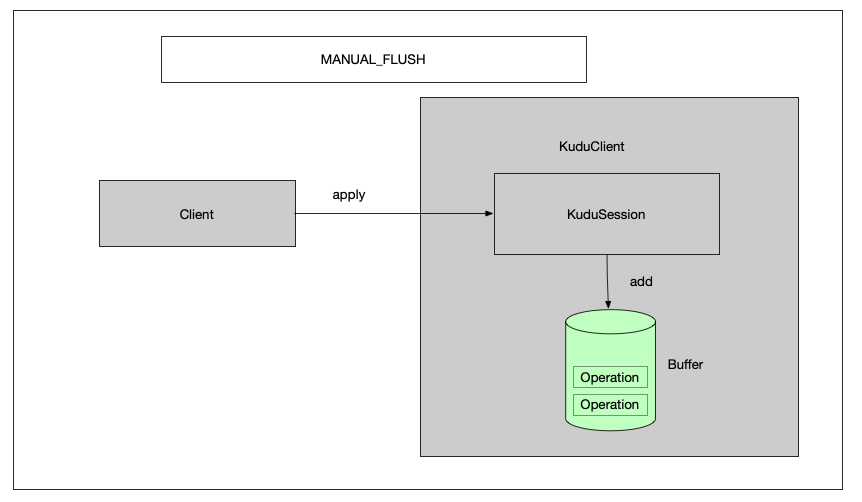
1.2 MANUAL_FLUSH 调用会立即返回,但是直到用户调用 KuduSession的flush()方法,才会发送write 。如果缓冲区运行超过 配置的空间限制(通过setMutationBufferSpace设置),那么apply将返回一个NonRecoverableException(MANUAL_FLUSH is enabled but the buffer is too big)错误。
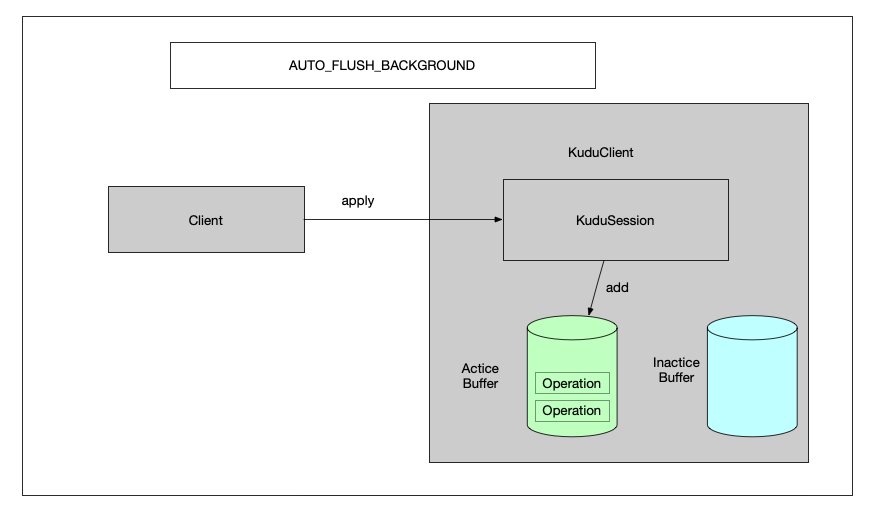
1.2.1 apply插入数据 在每个session内部,维护了一个 ActiveBuffer作为数据缓冲区来提高写入效率,因为全内存操作,所以方法调用会很快返回。如下图,client调用session的apply方法,并不会写入kudu tablet,而是放入到本地的缓冲区之中。
这个apply方法,其实并没有图中这么简单,里面涉及到很多很多异步调用,用到了stumbleupon异步框架,下面举个简单的例子说明一下
1 2 3 4 5 Deferred<String> hello = Deferred.fromResult("Hello" ); hello.addBoth(str -> { out.println(Thread.currentThread().getName() + " :1 " + str); return str + " hello" ; });
上面生成了一个Deferred对象,当执行这行代码的时候,会输出
其实这段代码类似于下面的一段代码
1 2 3 4 5 6 Deferred<String> hello = new Deferred <String>(); hello.addBoth(str -> { out.println(Thread.currentThread().getName() + " :1 " + str); return str + " hello" ; }); hello.callback("Hello" )
在KuduSession类中,很多应用了这种模式去生成调用链。在调用apply方法的时候,每个operation,都会先去查看这个operation所属的tablet,可能是从远程master中获取,也可能是从缓存中获取,如下。 下面的deferred并会作为一个属性放入BufferedOperation属性并加入到buffer中,这个BufferedOperation就是在后面flush的时候,就会为这个deferred新加一个TabletLookupCB回调,在这个回调中,批量插入数据
1 2 3 4 5 Deferred<LocatedTablet> tablet = client.getTabletLocation(operation.getTable(), operation.partitionKey(), LookupType.POINT, timeoutMillis);
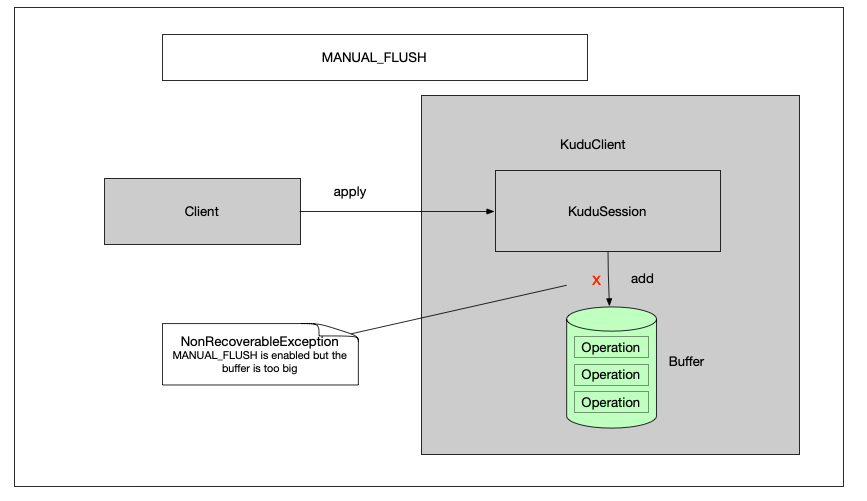
1.2.2 ActiveBuffer缓冲区满 如下图,在有三个缓冲区容量的情况下,再继续插入,则会跑出一个NonRecoverableException,提示 MANUAL_FLUSH is enabled but the buffer is too big 这个时候,就必须调用session的flush方法,将缓存区的数据写入到tablet中去。
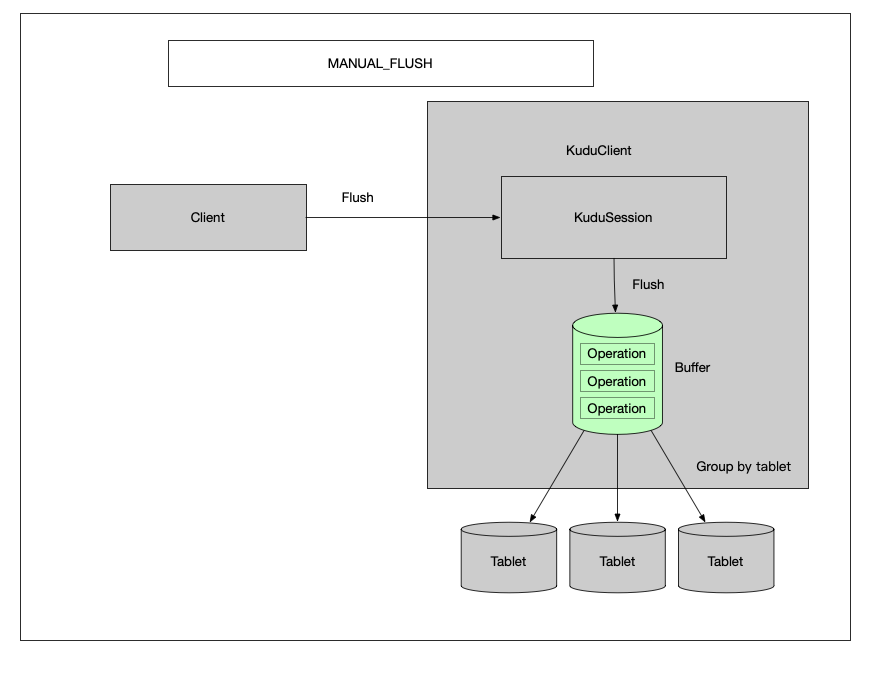
1.2.3 调用Flush方法刷写
flush流程分析
获取当前的activeBuffer
生成一个batchResponses Deferrd,用于在所有数据处理完成之后返回结果
初始化一个TabletLookupCB,在初始化的时候,会根据buffer中的operation长度初始化一个 lookupsOutstanding (AtomicInteger),值等于operations的长度,这个用于后面回调的时候,判断所有operation的tablet都获取完了, 起到一个栅栏的作用
将TabletLookupCB新加到每一个BufferOperation的deferred的callback链中去
每个operation的tabletLocate deffered 在完成后,都会调用 TabletLookupCB 的 call方法
在这里会判断lookupsOutstanding是否等于0了,如果不是,则减一
如果等于0了,则代表所有的都获取完了
根据每个operation所在的tablet分组,构建一个 一tabletId为分片的Map: Map<Slice, Batch> batches
分别调用 client.sendRpcToTablet 插入数据
为batchResponses 新加一个 ConvertBatchToListOfResponsesCB callbak,用于对返回结果的拼装
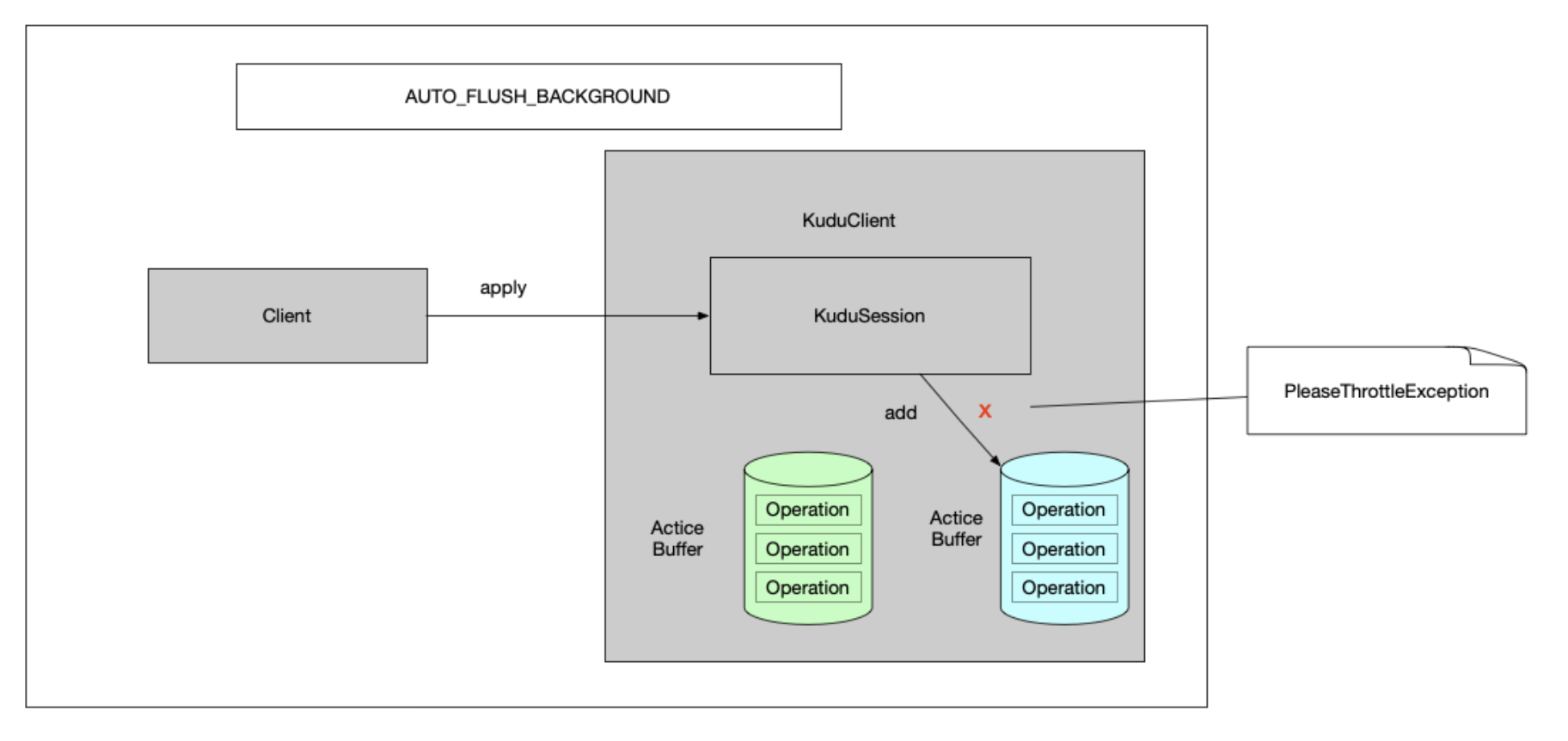
1.3 AUTO_FLUSH_BACKGROUND 调用将立即返回,写入将在后台发送,可能与来自同一会话的其他写入一起成批发送。如果没有足够的缓冲区空间,那么 KuduSession.apply() 可能阻塞可用的缓冲区空间。因为写操作是在后台进行的,所以错误都将 存储在会话本地缓冲区中。调用 countPendingErrors() countPendingErrors()}或getPendingErrors() getPendingErrors()}来获取响应错误数量和错误详情。
注意 :AUTO_FLUSH_BACKGROUND 模式可能会导致对Kudu的写操作顺序混乱。这是因为在这种模式下,多个写*操作可能会并行发送到服务器。
1.3.1 apply插入数据
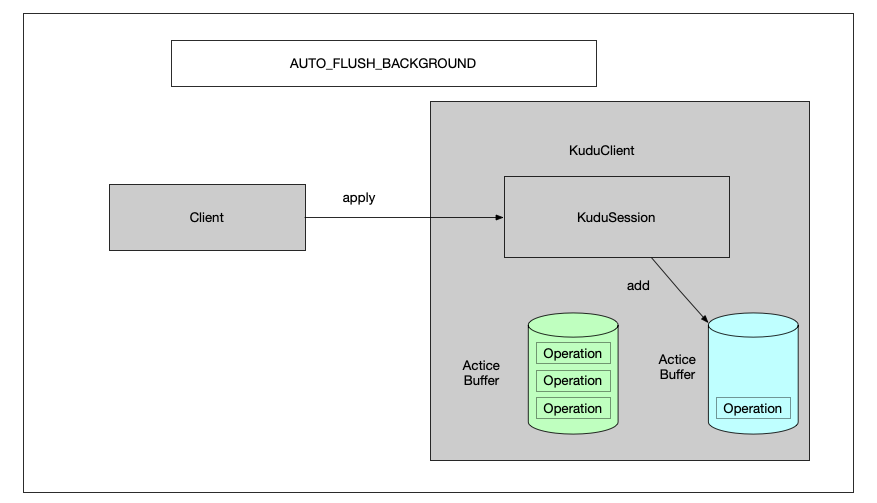
这里apply会先判断 activeBufferSize 的值是否大于mutationBufferMaxOps设置值
如果大于等于,则切换 一个 非活动的缓冲区为活动缓冲区
并且将当前缓冲区清空,复制为一个fullBuffer
如果没有满,则直接将operation插入的buffer中去
如果在第一步中fullBuffer有设置值,直接调用flush刷新
1.3.2 当一个buffer满的时候
1.3.3 当双buffer都满的时候
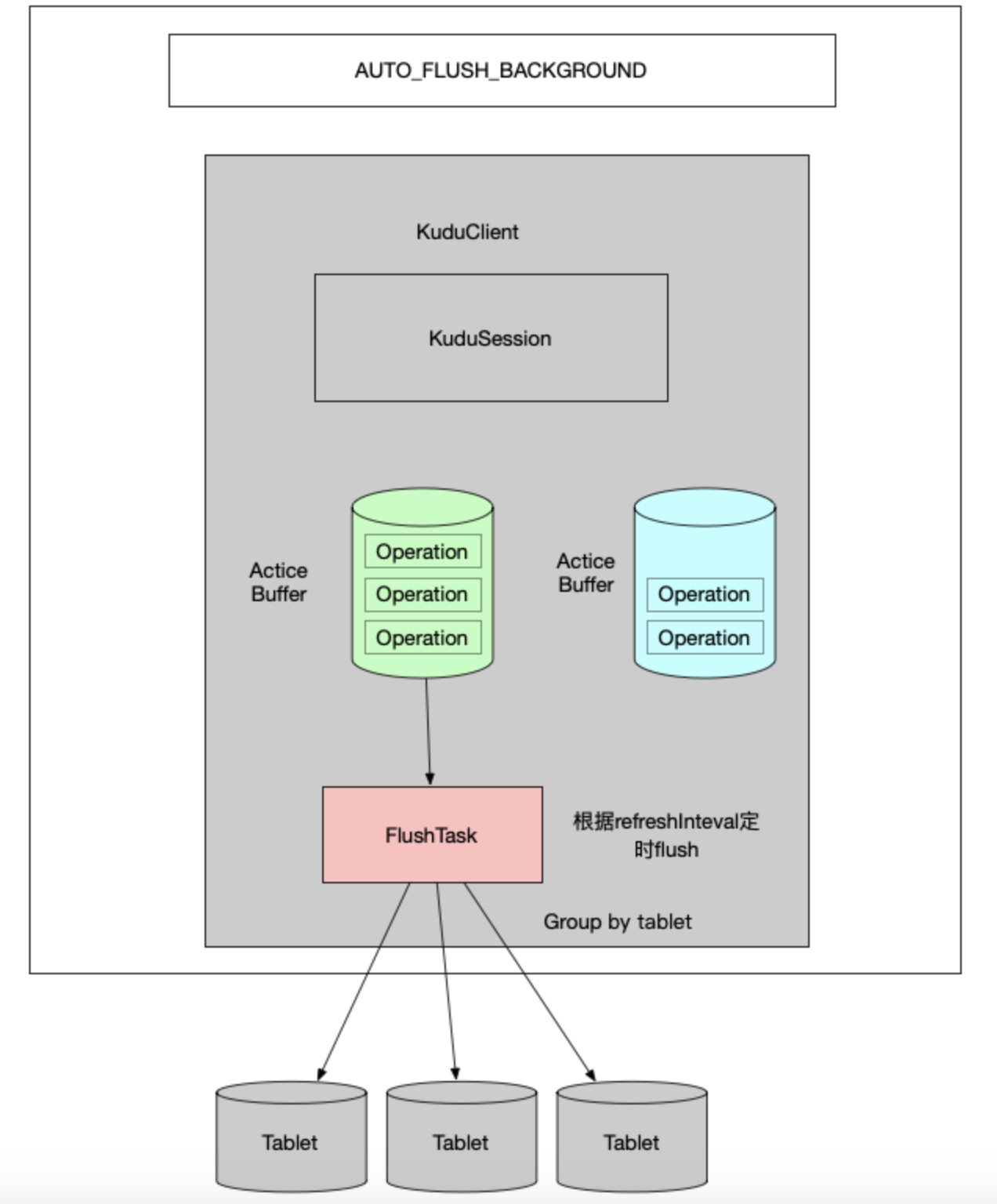
1.3.4 后台Flush线程定时刷新
二、性能对比 1. AUTO_FLUSH_SYNC 和 MANUAL_FLUSH对比 AUTO_FLUSH_SYNC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private static void autoFlushTest (KuduClient client) throws KuduException { KuduTable table = client.openTable("impala::default.my_first_table" ); KuduSession session = client.newSession(); session.setFlushMode(SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC); session.setTimeoutMillis(60000 ); int batch = 100 ; int startLine = 50000 ; try { long start = System.currentTimeMillis(); for (int i = startLine; i < startLine + batch; i++) { Insert insert = table.newInsert(); PartialRow row = insert.getRow(); row.addInt("id" , i); row.addString("name" , "xxx " + i); OperationResponse apply = session.apply(insert); RowError rowError = apply.getRowError(); System.out.println("rowError : " + ((rowError != null ) ? rowError.toString() : "No ERROR" )); long elapsedMillis = apply.getElapsedMillis(); System.out.println("elapsedMillis : " + elapsedMillis); } long used = System.currentTimeMillis() - start; System.out.println(batch + "s Total used " + used); } catch (KuduException e) { e.printStackTrace(); } finally { session.flush(); session.close(); } }
运行结果
MANUAL_FLUSH
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 private static void manualFlush (KuduClient client) throws KuduException { KuduTable table = client.openTable("impala::default.my_first_table" ); KuduSession session = client.newSession(); session.setMutationBufferSpace(5000 ); session.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH); session.setTimeoutMillis(60000 ); int batch = 100 ; int startLine = 50100 ; try { long start = System.currentTimeMillis(); for (int i = startLine; i < startLine + batch; i++) { Insert insert = table.newInsert(); PartialRow row = insert.getRow(); row.addInt("id" , i); row.addString("name" , "xxx " + i); session.apply(insert); } List<OperationResponse> flush = session.flush(); for (int i = 0 ; i < flush.size(); i++) { OperationResponse operationResponse = flush.get(i); RowError rowError = operationResponse.getRowError(); if (rowError != null ) { System.out.println("rowError : " + ((rowError != null ) ? rowError.toString() : "No ERROR" )); Operation operation = rowError.getOperation(); if (null != operation) { PartialRow row = operation.getRow(); System.out.println(" error row : " + row.toString()); } } } RowErrorsAndOverflowStatus pendingErrors = session.getPendingErrors(); RowError[] rowErrors = pendingErrors.getRowErrors(); for (int i = 0 ; i < rowErrors.length; i++) { RowError rowError = rowErrors[i]; System.out.println("rowError : " + ((rowError != null ) ? rowError.toString() : "No ERROR" )); Operation operation = rowError.getOperation(); if (operation != null ) { PartialRow row = operation.getRow(); System.out.println(" error row : " + row.toString()); } } long used = System.currentTimeMillis() - start; System.out.println(batch + "s Total used " + used); } catch (KuduException e) { e.printStackTrace(); } finally { session.flush(); session.close(); } }
运行结果
三、总结 个人感觉,kudu的客户端,做的还是比较初步的,对比hbase而言,少了很多可靠性方面的保证,而且缓冲区只考虑operation的条数(数量),而没有考虑到总的operation的大小,比如如果某一个插入列插入了一条很大的字符串,则可能一个批次就非常大,甚至造成客户端的内存溢出。
另外,在生产环境上,建议使用manualFlush批量手动提交的模式,这主要基于性能和灵活性方面的考虑。