
本文介绍kylin的构建任务的生成流程,包括前端如何请求的kylin服务端,服务端内部怎么调用生成任务并返回给前端以及内部如何调度的。
Kylin任务构建方法
一般构建Kylin是使用调度工具Azkaban或者Airflow来构建,在每天凌晨一点或者每个小时的第五分钟开始构建上一天或者上一个小时的数据。
比如我们公司就是在每个小时第五分钟开始构建,构建任务就是下图中的 server7_kylin_build,在构建之前会有一些准备工作,比如新建hive分区,数据检查等。server7_kylin_build就是一个python脚本,入参为当前构建任务的开始时间,在python中,会把这个时间作为kylin 一个segement的结束时间,然后通过python获取上一个小时作为开始时间,构建任务类型为BUILD,提交到 http://{kylin_host}:7070/kylin/api/cubes/{cube_name}/build 接口。
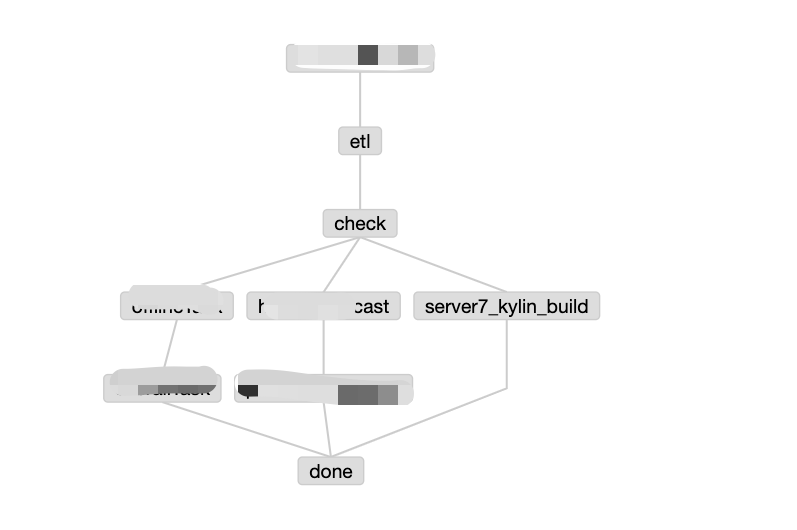

构建任务生成
构建接口Rest API
下面是摘自kylin构建接口的接口描述,摘自Apache Kylin | Use RESTful API
1
| PUT /kylin/api/cubes/{cubeName}/build
|
Path Variable
- cubeName -
required string Cube name.
Request Body
- startTime -
required long Start timestamp of data to build, e.g. 1388563200000 for 2014-1-1
- endTime -
required long End timestamp of data to build
- buildType -
required string Supported build type: ‘BUILD’, ‘MERGE’, ‘REFRESH’
Curl Example
1
| curl -X PUT -H "Authorization: Basic XXXXXXXXX" -H 'Content-Type: application/json' -d '{"startTime":'1423526400000', "endTime":'1423612800000', "buildType":"BUILD"}' http://<host>:<port>/kylin/api/cubes/{cubeName}/build
|
Response Sample
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| {
"uuid":"c143e0e4-ac5f-434d-acf3-46b0d15e3dc6",
"last_modified":1407908916705,
"name":"test_kylin_cube_with_slr_empty - 19700101000000_20140731160000 - BUILD - PDT 2014-08-12 22:48:36",
"type":"BUILD",
"duration":0,
"related_cube":"test_kylin_cube_with_slr_empty",
"related_segment":"19700101000000_20140731160000",
"exec_start_time":0,
"exec_end_time":0,
"mr_waiting":0,
"steps":[
{
"interruptCmd":null,
"name":"Create Intermediate Flat Hive Table",
"sequence_id":0,
"exec_cmd":"hive -e \"DROP TABLE IF EXISTS kylin_intermediate_test_kylin_cube_with_slr_desc_19700101000000_20140731160000_c143e0e4_ac5f_434d_acf3_46b0d15e3dc6;\nCREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_test_kylin_cube_with_slr_desc_19700101000000_20140731160000_c143e0e4_ac5f_434d_acf3_46b0d15e3dc6\n(\nCAL_DT date\n,LEAF_CATEG_ID int\n,LSTG_SITE_ID int\n,META_CATEG_NAME string\n,CATEG_LVL2_NAME string\n,CATEG_LVL3_NAME string\n,LSTG_FORMAT_NAME string\n,SLR_SEGMENT_CD smallint\n,SELLER_ID bigint\n,PRICE decimal\n)\nROW FORMAT DELIMITED FIELDS TERMINATED BY '\\177'\nSTORED AS SEQUENCEFILE\nLOCATION '/tmp/kylin-c143e0e4-ac5f-434d-acf3-46b0d15e3dc6/kylin_intermediate_test_kylin_cube_with_slr_desc_19700101000000_20140731160000_c143e0e4_ac5f_434d_acf3_46b0d15e3dc6';\nSET mapreduce.job.split.metainfo.maxsize=-1;\nSET mapred.compress.map.output=true;\nSET mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;\nSET mapred.output.compress=true;\nSET mapred.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;\nSET mapred.output.compression.type=BLOCK;\nSET mapreduce.job.max.split.locations=2000;\nSET hive.exec.compress.output=true;\nSET hive.auto.convert.join.noconditionaltask = true;\nSET hive.auto.convert.join.noconditionaltask.size = 300000000;\nINSERT OVERWRITE TABLE kylin_intermediate_test_kylin_cube_with_slr_desc_19700101000000_20140731160000_c143e0e4_ac5f_434d_acf3_46b0d15e3dc6\nSELECT\nTEST_KYLIN_FACT.CAL_DT\n,TEST_KYLIN_FACT.LEAF_CATEG_ID\n,TEST_KYLIN_FACT.LSTG_SITE_ID\n,TEST_CATEGORY_GROUPINGS.META_CATEG_NAME\n,TEST_CATEGORY_GROUPINGS.CATEG_LVL2_NAME\n,TEST_CATEGORY_GROUPINGS.CATEG_LVL3_NAME\n,TEST_KYLIN_FACT.LSTG_FORMAT_NAME\n,TEST_KYLIN_FACT.SLR_SEGMENT_CD\n,TEST_KYLIN_FACT.SELLER_ID\n,TEST_KYLIN_FACT.PRICE\nFROM TEST_KYLIN_FACT\nINNER JOIN TEST_CAL_DT\nON TEST_KYLIN_FACT.CAL_DT = TEST_CAL_DT.CAL_DT\nINNER JOIN TEST_CATEGORY_GROUPINGS\nON TEST_KYLIN_FACT.LEAF_CATEG_ID = TEST_CATEGORY_GROUPINGS.LEAF_CATEG_ID AND TEST_KYLIN_FACT.LSTG_SITE_ID = TEST_CATEGORY_GROUPINGS.SITE_ID\nINNER JOIN TEST_SITES\nON TEST_KYLIN_FACT.LSTG_SITE_ID = TEST_SITES.SITE_ID\nINNER JOIN TEST_SELLER_TYPE_DIM\nON TEST_KYLIN_FACT.SLR_SEGMENT_CD = TEST_SELLER_TYPE_DIM.SELLER_TYPE_CD\nWHERE (test_kylin_fact.cal_dt < '2014-07-31 16:00:00')\n;\n\"",
"interrupt_cmd":null,
"exec_start_time":0,
"exec_end_time":0,
"exec_wait_time":0,
"step_status":"PENDING",
"cmd_type":"SHELL_CMD_HADOOP",
"info":null,
"run_async":false
},
{
"interruptCmd":null,
"name":"Extract Fact Table Distinct Columns",
"sequence_id":1,
"exec_cmd":" -conf C:/kylin/Kylin/server/src/main/resources/hadoop_job_conf_medium.xml -cubename test_kylin_cube_with_slr_empty -input /tmp/kylin-c143e0e4-ac5f-434d-acf3-46b0d15e3dc6/kylin_intermediate_test_kylin_cube_with_slr_desc_19700101000000_20140731160000_c143e0e4_ac5f_434d_acf3_46b0d15e3dc6 -output /tmp/kylin-c143e0e4-ac5f-434d-acf3-46b0d15e3dc6/test_kylin_cube_with_slr_empty/fact_distinct_columns -jobname Kylin_Fact_Distinct_Columns_test_kylin_cube_with_slr_empty_Step_1",
"interrupt_cmd":null,
"exec_start_time":0,
"exec_end_time":0,
"exec_wait_time":0,
"step_status":"PENDING",
"cmd_type":"JAVA_CMD_HADOOP_FACTDISTINCT",
"info":null,
"run_async":true
},
{
"interruptCmd":null,
"name":"Load HFile to HBase Table",
"sequence_id":12,
"exec_cmd":" -input /tmp/kylin-c143e0e4-ac5f-434d-acf3-46b0d15e3dc6/test_kylin_cube_with_slr_empty/hfile/ -htablename KYLIN-CUBE-TEST_KYLIN_CUBE_WITH_SLR_EMPTY-19700101000000_20140731160000_11BB4326-5975-4358-804C-70D53642E03A -cubename test_kylin_cube_with_slr_empty",
"interrupt_cmd":null,
"exec_start_time":0,
"exec_end_time":0,
"exec_wait_time":0,
"step_status":"PENDING",
"cmd_type":"JAVA_CMD_HADOOP_NO_MR_BULKLOAD",
"info":null,
"run_async":false
}
],
"job_status":"PENDING",
"progress":0.0
}
|
这里返回的是一个JobInstance实例,主要描述了任务的一些运行时状态,比如运行时间、运行开始时间、结束时间、每个步骤的详情、当前的状态等。
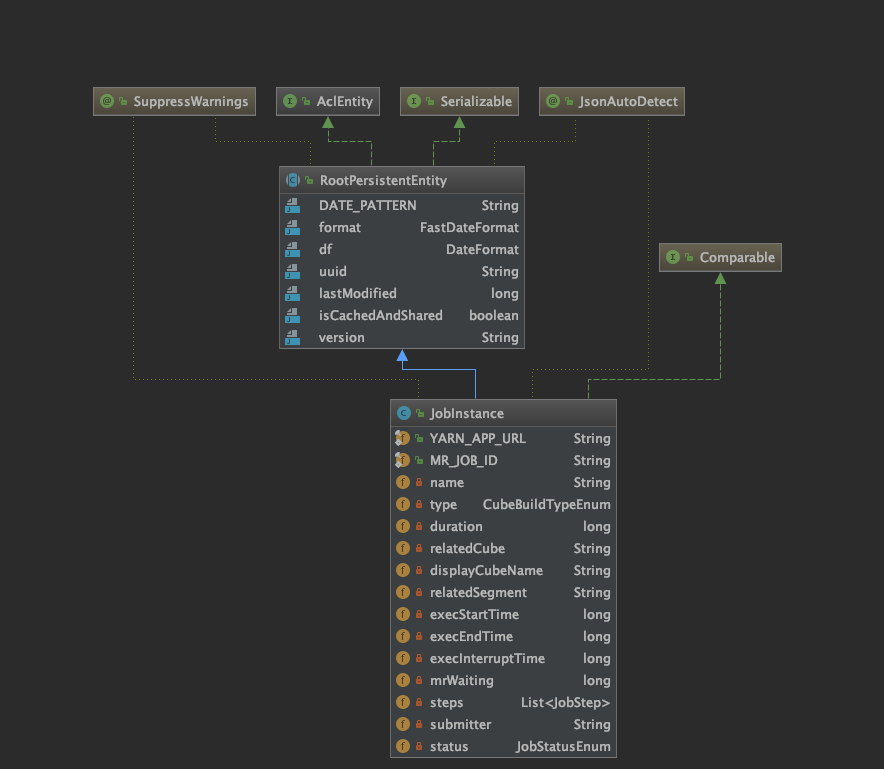
任务生成流程
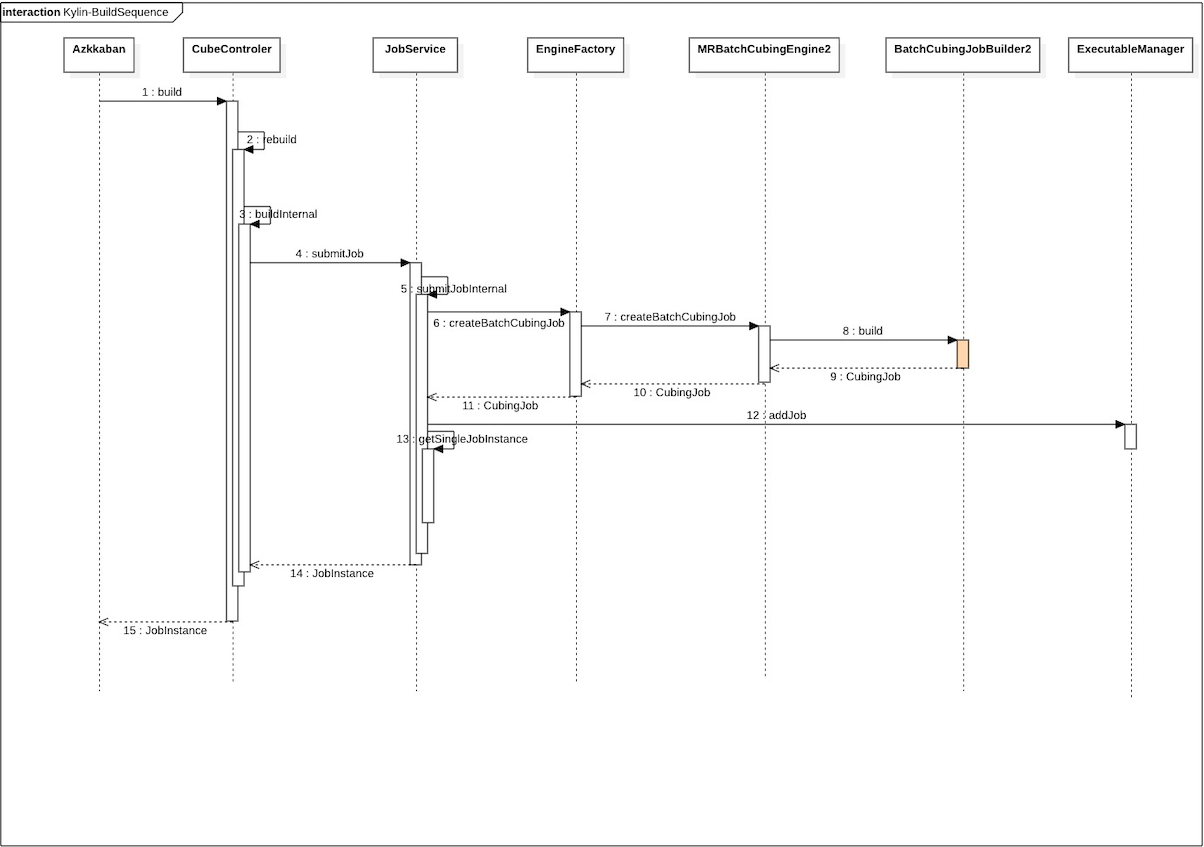
步骤详解
build
调用rebuild接口
rebuild
直接调用私有方法buildInternal
这一步会根据开始时间和结束时间实例化一个TSRange,用于表示segemnt的范围
buildInternal
调用JobService的submitJob方法
submitJob
调用submitJobInternal方法
submitJobInternal(核心方法)
- 这一步会调用EngineFactory.createBatchCubingJob方法生成一个CubingJob实例,这个实例是DefaultChinedExcutable的子类。
EnginFactory.createBatchCubingJob
这一步是在当前本地线程变量中获取一个IBatchCubingEngine的子类,我们选用的MR,所以这里返回的就是MRBatchCubingEngine2类
MRBatchCubingEngine2.createBatchCubingJob
这一步直接实例化一个BatchCubingJobBuilder2类,传入当前的segment,并且调用build方法,具体的调用流程将在后面的章节中详细分析
addJob
这一步会将改job序列化存入到hbase之中,带后面的FetcherRunner线程定期从hbase中拿出待执行的任务正式执行。
1
2
|
getExecutableManager().addJob(job);
|
任务调度与执行
本章节介绍在任务被添加并加入到hbase之后,如何被调度执行的。
Kylin调度器
Kylin调度器负责构建、合并等任务的调度与执行,目前有三种实现,分别为DefaultScheduler、DistributedScheduler、NoopScheduler。
DefaultScheduler
默认调度器,这种一般使用在只有一个kylin model为server的集群中(单构建节点),使用Java线程池来执行构建任务,并且使用一个,使用一个定时调度任务 FetcherRunner 来定期从hbase中拿出构建任务,并放入到任务池中等待调度执行。
DistributedScheduler
分布式调度器,当多个构建服务器运行在相同元数据上的时候使用。内部使用Zookeeper来管理分布式状态。开启分布式调度器需要修改kylin.properties
- kylin.job.scheduler.default=2
- kylin.job.lock=org.apache.kylin.storage.hbase.util.ZookeeperJobLock
- add all the job servers and query servers to the kylin.server.cluster-servers
NoopScheduler
没有任何实现,什么都不做
调度器初始化
下图为初始化流程,主要的初始化入口在JobService类中,它是一个Spring托管的bean,在该bean初始化之后,会调用afterPropertiesSet方法,在这个方法中根据配置获取调度器,并异步调用init方法进行初始化。最后会加一个钩子,在系统关闭的时候关闭调度器。
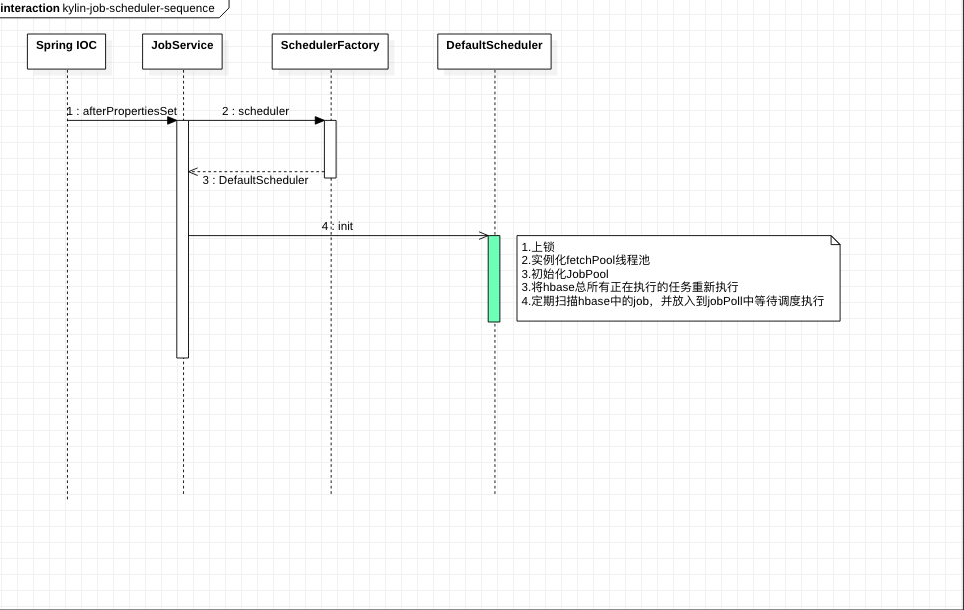
初始化具体方法。限于篇幅,DefaultScheduler的init方法源码没有贴出,但是可以参考 DefaultScheduler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| @Override
public void afterPropertiesSet() throws Exception {
String timeZone = getConfig().getTimeZone();
TimeZone tzone = TimeZone.getTimeZone(timeZone);
TimeZone.setDefault(tzone);
final KylinConfig kylinConfig = KylinConfig.getInstanceFromEnv();
final Scheduler<AbstractExecutable> scheduler = (Scheduler<AbstractExecutable>) SchedulerFactory
.scheduler(kylinConfig.getSchedulerType());
new Thread(new Runnable() {
@Override
public void run() {
try {
scheduler.init(new JobEngineConfig(kylinConfig), new ZookeeperJobLock());
if (!scheduler.hasStarted()) {
logger.info("scheduler has not been started");
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}).start();
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
try {
scheduler.shutdown();
} catch (SchedulerException e) {
logger.error("error occurred to shutdown scheduler", e);
}
}
}));
}
|
调度执行
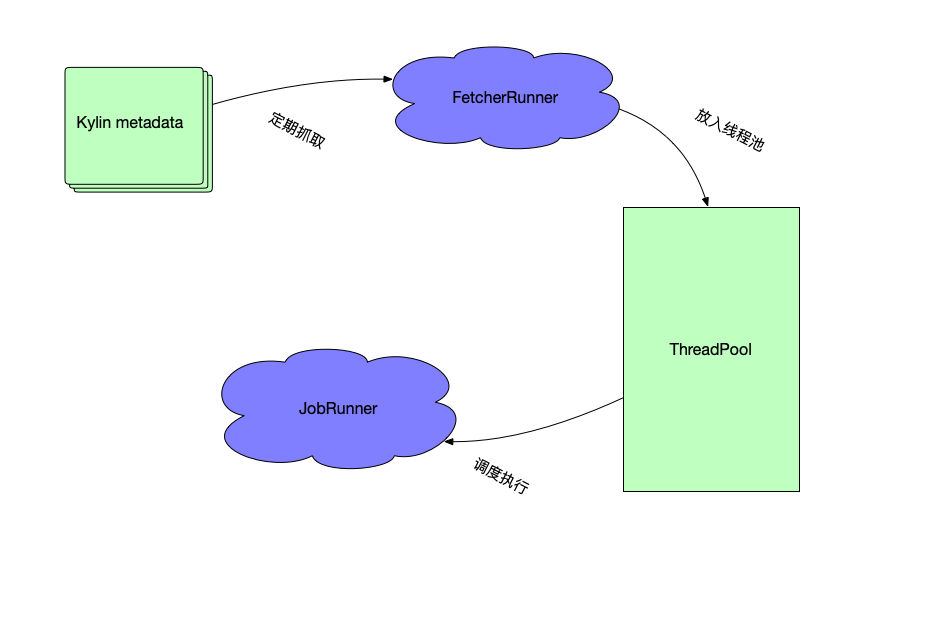
CubingJob分析
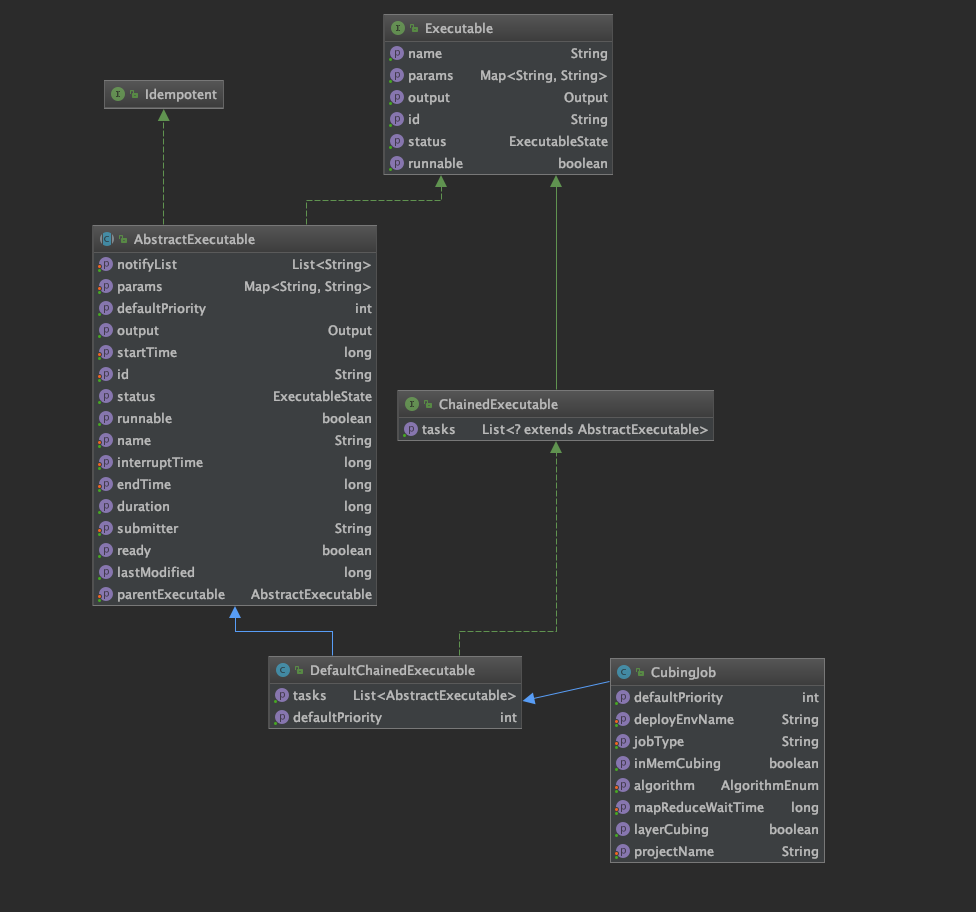
先从上往下介绍,Executable是一个接口,主要方法是 ExecuteResult execute(ExecutableContext executableContext),子类实现这个方法,会在调度的时候传入上下文,返回执行结果。
AbstractExecutable是一个抽象类,实现了execute这个方法,主要实现了一些公共的逻辑,比如执行前的预处理、执行后的修改状态、错误重试、邮件通知等公共操作。 在execute方法中使用了 do…while循环执行retry次子类实现的doWork方法。
CubingJob主要类图如下,该类是一个链式可执行类,所谓链式,就是有一系列的子任务组成的一个大任务,链式执行的实现在DefaultChainedExecutable类中,在它执行方法doWork中,循环实现job的tasks列表,而这些tasks列表中的task,也是Executable的子类,理论上也可以是链式任务。
下面是链式任务的doWork方法,可以看到,会根据子任务的状态做相应的逻辑判断,如果正在执行,说明当前的job已经有子任务在执行了,不必要启动一个新的subtask,如果是STOPPED,说明已经停止,无须再次执行,如果是可执行的,则执行这个子任务,并且把结果返回。 请注意这里直接返回了,没有继续循环,也就是说,链式任务,一次只会执行一个子任务,执行完成就返回,并且等待下一次调度继续执行子任务。 如果没有子任务了,则直接返回成功,整个链式任务执行成功。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| protected ExecuteResult doWork(ExecutableContext context) throws ExecuteException {
List<? extends Executable> executables = getTasks();
final int size = executables.size();
for (int i = 0; i < size; ++i) {
Executable subTask = executables.get(i);
ExecutableState state = subTask.getStatus();
if (state == ExecutableState.RUNNING) {
break;
} else if (state == ExecutableState.STOPPED) {
break;
} else if (state == ExecutableState.ERROR) {
throw new IllegalStateException(
"invalid subtask state, subtask:" + subTask.getName() + ", state:" + subTask.getStatus());
}
if (subTask.isRunnable()) {
return subTask.execute(context);
}
}
return new ExecuteResult(ExecuteResult.State.SUCCEED);
}
|
可以看看都有哪些类实现了Executable,比如建Hbase表、建Hive宽表、以及提交MR程序的MapreduceExecutable、清理HDFS临时文件等等,在后面的章节中会详细介绍这些是如何实现的。

总结
基于上面的描述,我们了解了一般工作中的kylin的构建方法,以及构建的详细流程,其中关键方法是submitJobInternal,会调用EnginFacotry获取Builder,然后构建任务,并且会加入到hbase中。
后面还详细介绍了kylin的三种执行器,DefaultScheduler、DistributeSchedule以及NooopScheduler,以及介绍了默认调度器的初始化流程和任务从产生到开始运行的详细过程。
下一章将会详细介绍任务构建过程。
Kylin源码解析系列目录
构建引擎系列
1、Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想
2、Kylin源码解析-kylin构建流程总览 | 编程狂想
3、Kylin源码解析-构建引擎实现原理 | 编程狂想
4、Kylin源码解析-生成Hive宽表及其他操作 | 编程狂想
5、Kylin源码解析-提取事实表唯一列 | 编程狂想
6、Kylin源码解析-构建层级分析 | 编程狂想
7、Kylin源码解析-构建数据字典和生成Cuboid统计数据
8、Kylin源码解析-生成Hbase表
9、Kylin源码解析-构建Cuboid
10、Kylin源码解析-转换HDFS为Hfile
11、Kylin源码解析-加载Hfile到Hbase中
12、Kylin源码解析-修改元数据以及其他清理工作
查询引擎系列