
方法介绍
这一步是Kylin运行MR任务来提取使用字典编码(rowkey配置也的编码类型为dict)的维度列的唯一值。
1 | //构建方法 |
上面这一步就是提取事实表唯一列的链式子任务的构建方法,返回的是一个MapReduceExecutable,它是AbstractExecutable的子类,在doWork方法中,会调用一个AbstractHadoopJob的子类的run方法,在run方法中,会将该任务提交到Yarn上面执行。也就是说,这是MR任务的提交入口。
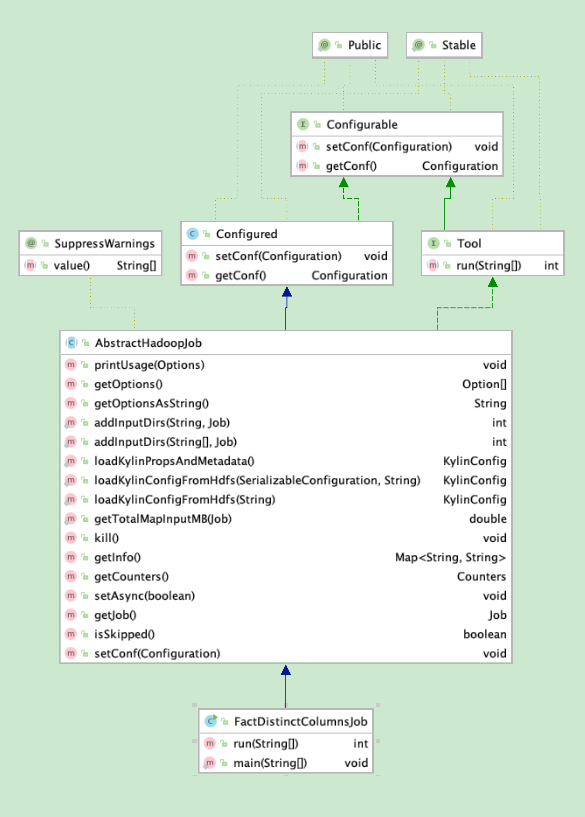
FactDistinctColumnsJob就是AbstractHadoopJob的一个子类,这些类型初始化的时候都会设置好 mapper、combinaer、partitioner、reducer等类,下面就是FactDistinctColumnsJob的相关类图。核心方法就是实现类的 run 方法,会设置输入和输出,classpath等,然后提交调用父类AbstractHadoopJob的waitForCompletion提交到Yarn集群。抽象类AbstractHadoopJob提供了一些公用的方法,比如获取classpath。
输入解析
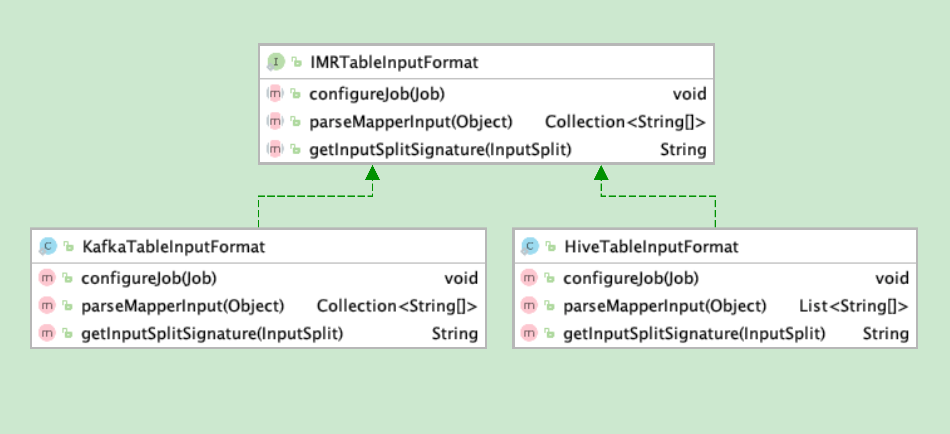
这里要介绍这一步的输入,这一步是读取第二步中生中的成的Hive宽表。在Kylin中,有多重不同的MR任务,有的任务输入是Hive表,有的则是存储在HDFS中的中间数据,所以kylin提供了IMRTableInputFormat接口,是一个工具类,用于配置mapper去读取hive table。如果是HDFS,则是调用另外一个IMROutput2接口下面的子接口IMROutputFormat的configureJobInput方法,为什么要这么设计了?我想大概是因为这些中间数据最后都为经过处理写入hbase吧。
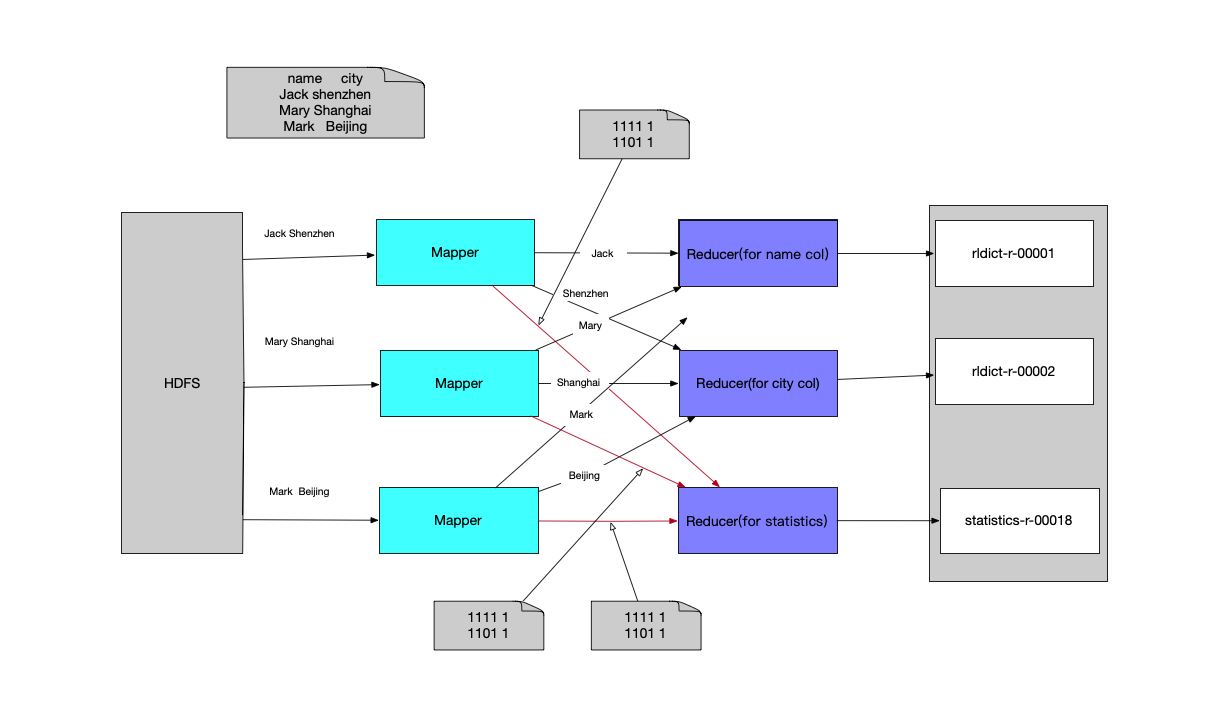
数据流向举例
下面是一个简单任务的数据流向示意图,假设一个表有两个字段 name 和 city,示例数据如下表
| name | City |
|---|---|
| Jack | Shenzhen |
| Mary | Shanghai |
| Mark | Beijing |
假如在最理想的情况下,这个表的三条数据均匀分布在三个hdfs block上,则会有三个mapper,一个mapper读取一条记录。并且会根据维度列的数量来设置有多少个reducer,一般情况会设置维度列的数量n+1个reducer,前面n个reducer分别处理每一个列的值,这样不同mapper的同一列会发送到相同的列,这样就可以去重了。最后一个reducer主要处理统计抽样的任务。每一个mapper都会有cuboidCount个HLLCounter,对每个cuboid进行抽样统计计数,在cleanup阶段,会发送到最后一个reducer进行聚合和汇总。这个汇总在统计sgement的总的大小或者在列出segemnt的cuboid的树形目录(bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader CUBE_NAME)的时候会用到。
FactDistinctColumnsMapper介绍
Setup阶段
- 获取所有的cuboidIds和nRowKey(总的rowkey个数)
- 从配置文件获取抽样比例,默认为100
- 构建allCuboidsBitSet
- 返回一个二维数组,第一维长度是总的cuboid的数量,比如只有两个合法的cuboid, 则长度为2,第二维的长度是这个cuboid中为1的位的数量,而值,就是这个在rowkey中的下标
- 构建allCuboidsHLL,每一个cuboid一个HLLCounter,用于非精确统计数量
- 构建CuboidStatCalculator数组,CuboidStatCalculator是一个线程,抽样统计的执行者。
- 这里会根据cuboid的数量进行分片,比如如果cuboid数量太多,就会有多个线程来执行hll counter,这事一个划分分片的逻辑,比如从 0 到 splitSize 的给一个 calculator处理,以此类推。
doMap阶段
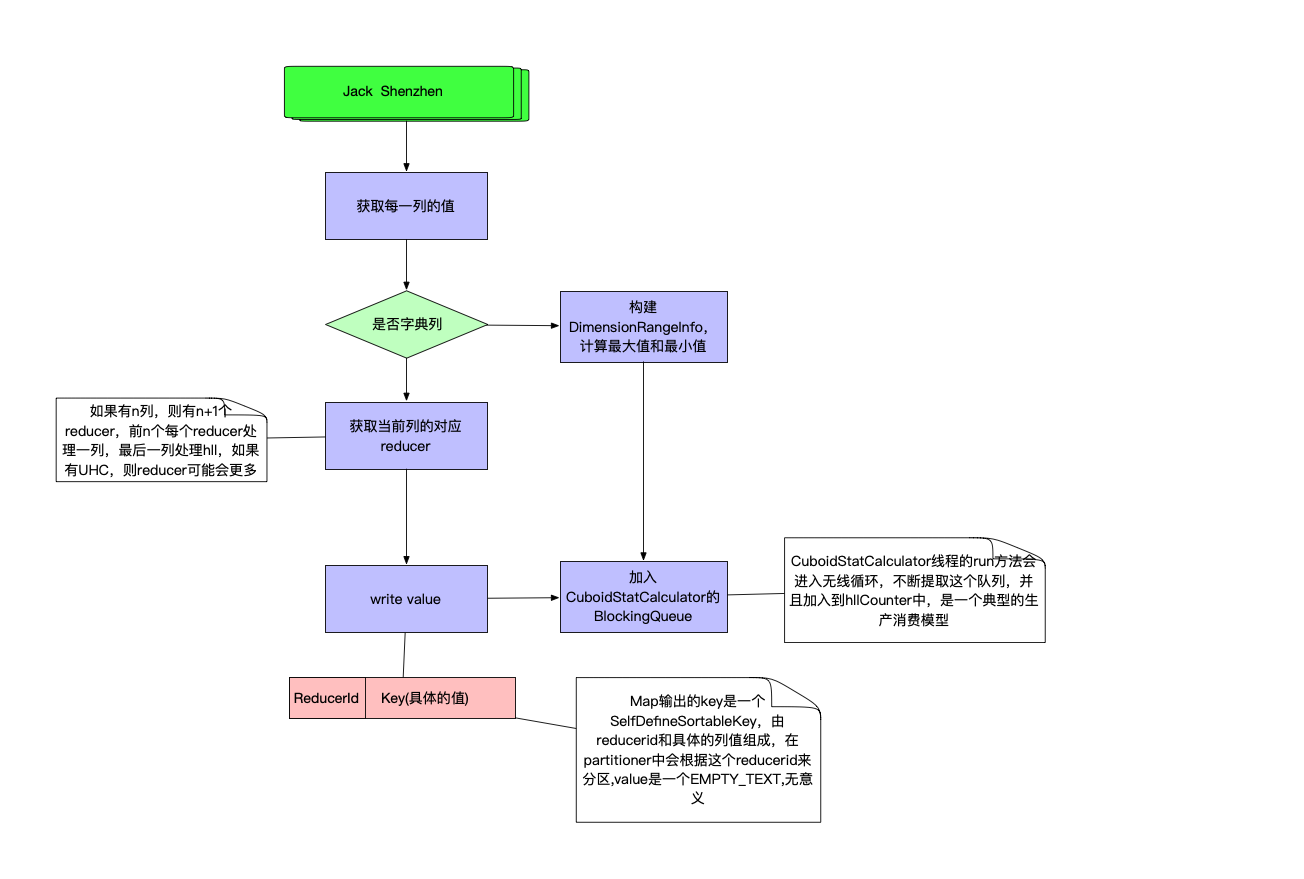
cleanUp阶段
- 停止CuboidStatCalculator线程
- 遍历CuboidStatCalculator数组,输出每一列的hll统计值,这里的key的第一位占位符是MARK_FOR_HLL_COUNTER,是专门用于计算hll的,默认是最后一个reducer。value是hll计算的count值
- 遍历dimensionRangeInfoMap,输出这些非字典维度的最大值和最小值。
FactDistinctColumnsReducer介绍
Setup阶段
- 根据taskid判断当前reducer的角色,是普通列的reducer还是hll计算的reducer
- 如果是普通列reducer,则根据配置判断是否在reducer中构建字典,如果是,则初始化一个字典构建器
doReduce阶段
- 获取当前key
- 如果是hll counter
- 获取cuboid,因为每个mapper都会计算cuboid,所以这里需要把不同的mapper的hll做一个merge。
- 遍历values
- 这里有一个 Map<Long, HLLCounter> cuboidHLLMap
- 在遍历的时候会去map里面去取对应的hllCounter,如果取到了,则merge取到的hll和当前的hll
- 如果没有取到,则将当前的hll放入
- 如果不是hll counter
- 拿到当前的key
- 判断当前列是否是字典维度列(因为有的列是字典列,有的不是)
- 如果不是,这计算出当前的最大值和最小值,这个值在cleanUp阶段会输出
- 如果是字典列
- 如果在reducer阶段构建,则builder加入这个值
- 如果不在reducer阶段构建,则直接通过 MultipleOutputs 输出到不同的文件中去,MultipleOutputs的用法参考MultipleOutputs实现MapReduce多个输出 | 时间与精神的小屋
cleanUp阶段
- 统计reducer
- 输出统计信息到指定目录
- 列 reducer
- 如果不是字典维度列,则输出 最小值和最大值到指定目录
- 如果是维度列,并且是在reducer端构建的,则构建字典,输出到 fact_distinct_columns 目录下,如果不在reducer端构建,则不作操作,后面构建字典的步骤的时候,会读取在reducer端写的文件再次进行构建。
总结
本章节详细介绍了抽取事实表唯一列的任务创建、相关类图、以及Mapper、Reducer的代码逻辑,主要核心是reducer的划分,以及相关任务的分配和HLLCounter的应用。在后面会继续介绍构建字典相关的知识。
Kylin源码解析系列目录
构建引擎系列
1、Kylin源码解析-kylin构建任务生成与调度执行 | 编程狂想
2、Kylin源码解析-kylin构建流程总览 | 编程狂想
4、Kylin源码解析-生成Hive宽表及其他操作 | 编程狂想
7、Kylin源码解析-构建数据字典和生成Cuboid统计数据
8、Kylin源码解析-生成Hbase表
9、Kylin源码解析-构建Cuboid
10、Kylin源码解析-转换HDFS为Hfile
11、Kylin源码解析-加载Hfile到Hbase中
12、Kylin源码解析-修改元数据以及其他清理工作