
维度和度量在kylin中是非常重要的基础概念,对这些概念有一个清晰的理解,有助于我们进一步加深对kylin的研究与应用
1 维度
1.1 定义
维度是观察数据的角度,一般是一组离散的值.
1.2 例子
这里举一个形象但是可能在现实开发中不会用到的一个例子,如下面的表格 “学生成绩表” ,是一个简单的事实表,有四个维度,分别是 name 名字, city 城市,class 班级,sex 性别,并且有一个用于聚合的列 grade 成绩。
则观察这个数据表的角度就可以有很多,可以从城市角度、班级角度、性别角度、甚至各个角度的组合来观察。 比如男生的成绩之和,男生的平均成绩,来自湖北的学生的最大成绩等等。
如果有n个维度列,则理论上的维度组合有2的N次方个。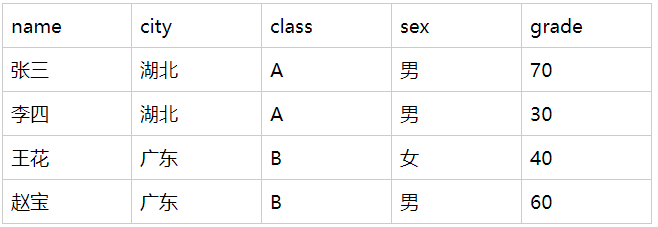
下面举几个常见的维度:
- 性别维度查看总分
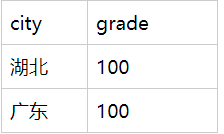
- 城市维度查看总分
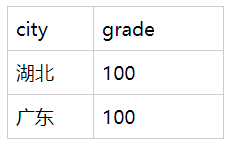
- 城市与性别维度查看总分
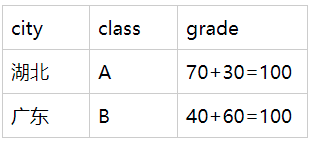
1.3 维度的基数
1.3.1 定义
维度的基数(Cardinality)指的是这个维度在数据集中出现不同值得个数。 比如上表中city这个维度,有湖北、广东、湖南、北京等34个值,则该维度的基数就是34。
1.3.2 超高基数列(Ultra High Cardinality,UHC)
超高基数列是指基数超过一百万的维度,这种维度的设计需要格外谨慎。常见的比如 “userid”、“timestamp”、“production_id”等等。维度的基数可以通过hive 的count distinct函数来进行查询获得。
这种字段一般重复度很低,一般会超过几百万上千万的,而且一般是Number类型的,所以在kylin中可以使用integer类型或者fix_length类型,其中integer类型是最合适的。 但是对于UHC,使用字典类型是不合适的,因为超高的基数,会使字典的体量非常大,kylin会将字典所有的值都加载进内存,导致对堆内存的消耗非常可观。如果一个数据集中有多个UHC,最好还使用kylin的高级特性聚合组来对维度进行分组,将某一个UHC和必须和这个UHC一起使用的维度分在一个聚合组中,避免两个或者多个UHC同时出现在一个分组中,导致cube膨胀。
2 度量
2.1 定义
度量就是被聚合的统计值,也是聚合运算的结果,一般是连续的值
2.2 例子
就像上面那个例子,总成绩就是度量,亦或者是平均成绩 avg(grade),或者是最大成绩 max(grade) 。度量主要用于分析或者评估,比如对趋势的判断,对业绩或者效果的判定等等。比如在一般的大数据分析应用里面就有总PV,总UV等度量用于评判一个网站或者APP的活跃度。